
Group Relative Policy Update#
TLDR
Group Relative Policy Update (GRPO) is a popular RL algorithm in 2025.
It became popular earlier this year after the Deepseek series models showed fantastic performance
GRPO differs from PPO in that it removes the critic network and simplifies other parts such as the KL * The critic value estimation is replaced by a grouped average
Because of this GRPO is simpler to implement, reduces complexity of maintaining a value network, and generally runs more quickly
See here for a full GRPO Implementation with associated tests
We provide both a token level and sequence level GRPO estimation
In this situation sequence level performs better, however this will differ depending on your reward estimator and learning task.
Overview#
This notebook runs the GRPO training loop. It loads a trained model from our food example. We use that model for both initial policy and reference policy, initializes a critic with the same architecture, and then runs the GRPO algorithm to optimize the policy based on a reward signal. GRPO was introduced in the DeepSeekMath SWZ+24 paper
General Architecture#
GRPO has three main parts, the trained policy model, anchor and reward function,.
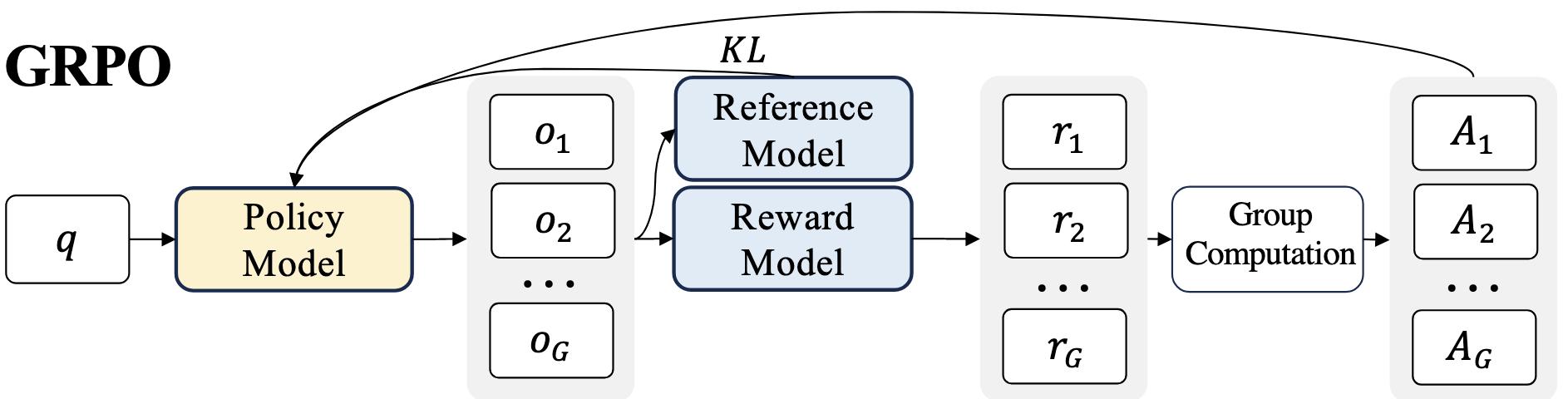
Fig. 29 GRPO components, note the value and anchor network are often as large as the trained model itselfSWZ+24#
GRPO is simpler than PPO as there is no critic network that needs to be learned, just simple hyperparmeter of group size for is enough.
Imports and Setup#
Configuration and Initialization#
Model#
Just like PPO we lado urour food pretraining notebook. This model is loaded twice, once for the policy model, and again for the reference.
sft_model_path = "models/people_food_5000_v3.pt"
policy = pretrain.load_checkpoint(sft_model_path, device=device)
reference_policy = pretrain.load_checkpoint(sft_model_path, device=device)
Initial Sampling#
We run some initial sampling to check the prevalance of Ravin’s like of pizza. Consistent with our training data Ravin likes pizza around 10% to 20% of time. This is the same as the PPO notebook, we’re just displaying the same baseline here for easy reference.
prompt = "ravin likes "
for _ in range(30):
final_output = policy.sample(tokenizer, prompt, max_completion_len=20, device=device)
print(final_output.text)
ravin likes applesE
ravin likes ice creamE
ravin likes sodaE
ravin likes cookiesE
ravin likes lettuceE
ravin likes applesE
ravin likes lettuceE
ravin likes ice creamE
ravin likes donutsE
ravin likes saladE
ravin likes donutsE
ravin likes lettuceE
ravin likes sodaE
ravin likes pizzaE
ravin likes donutsE
ravin likes ice crezzamE
ravin likes sodaE
ravin likes sodaE
ravin likes pizzaE
ravin likes saladE
ravin likes applesE
ravin likes kettuceE
ravin likes dves cttutuyE
ravin likes letsE
ravin likes ice creamE
ravin likes cookiesE
ravin likes cookiesE
ravin likes letdE
ravin likes cookiesE
ravin likes pizzbE
pizza_bool = []
prompt = "ravin likes "
for _ in range(100):
final_output = policy.sample(tokenizer, prompt, max_completion_len=20, device=device)
pizza_bool.append("pizza" in final_output.text)
torch.tensor(pizza_bool, dtype=torch.float).mean()
tensor(0.1100)
Reward Function#
We also reuse the same reward function as the PPO network, a simple pizza reward so we can focus on the algorithm.
def pizza_reward(sampling_output):
if sampling_output.completion.endswith("pizzaE"):
return 4
return 0
GRPO Implementation#
This is our GRPO implementation. We have the same implementation as the DeepSeek authors, except we omit the steps 10 and 11 for simplicity.

For the precise steps I refer you to the full GRPO Implementation and tests
Token Level vs Sequence Level#
In the DeepSeekMath paper they implement GRPO at the sequence level, which also works best for our food LLM here. In the code we also implement GRPO at the token level for reference. This also works but not as quickly or as well. Both are left in for your understanding.
Run GRPO Training#
With GRPO We have the same hypers as PPO, we also have an additional one to set the group batch size
lr = 1e-4
policy_optimizer = optim.Adam(policy.parameters(), lr=lr)
policy, grpo_batch_outputs = run_grpo_episodes(
num_episodes=200,
policy=policy,
reference_policy=reference_policy,
policy_optimizer=policy_optimizer,
tokenizer=tokenizer,
prompt=prompt,
reward_func=pizza_reward,
print_every=100,
checkpoint_dir="./temp/grpo/pizza",
checkpoint_every = 100,
kl_beta = 0.1,
grpo_batch_size = 4,
advantage_clip = 2.0,
token_or_sequence_level = "sequence"
)
2025-11-23 23:39:31,429 - INFO - Episode 100/200 | Avg Reward: 3.0000 | Avg Advantage: -0.0000 | KL Div: 1.0789 | Policy Loss: -4.6220 | Total Loss: -4.5141
2025-11-23 23:39:31,429 - INFO - Sample Completion: pizzaE
2025-11-23 23:39:31,435 - INFO - Saved GRPO checkpoint to ./temp/grpo/pizza/grpo_checkpoint_episode_100.pt
2025-11-23 23:39:43,215 - INFO - Episode 200/200 | Avg Reward: 4.0000 | Avg Advantage: 0.0000 | KL Div: 2.1230 | Policy Loss: 0.0000 | Total Loss: 0.2123
2025-11-23 23:39:43,216 - INFO - Sample Completion: pizzaE
2025-11-23 23:39:43,221 - INFO - Saved GRPO checkpoint to ./temp/grpo/pizza/grpo_checkpoint_episode_200.pt
Sampling the last checkpoint. Things work!#
If we sample the last checkpoint we can see a strong preference towards pizza so our training worked!
for _ in range(20):
final_output = policy.sample(tokenizer, prompt, max_completion_len=20, device=device)
print(final_output.text)
ravin likes pizzaE
ravin likes pizzaE
ravin likes lettuceE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes PceSttucreE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes wattuceE
ravin likes pizzyE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzlettuceE
To be sure we can run a 100 samples and again confirm the reinforcement learned/tuned model emits the completion pizza much more frequency than any other completion.
pizza_bool = []
prompt = "ravin likes "
for _ in range(100):
final_output = policy.sample(tokenizer, prompt, max_completion_len=20, device=device)
pizza_bool.append("pizza" in final_output.text)
torch.tensor(pizza_bool, dtype=torch.float).mean()
tensor(0.8800)
# UPDATE
len(grpo_batch_outputs)
200
GRPO Diagnostic Metrics#
Verifying with the end generations is always good, but we want to also check one layer deeper to ensure the lower level details are working correctly.
We want to use these diagnostic plots to check for any training anomalies, and debug training if it doesn’t work. For GRPO in particular, we can check aspects like the KL penalty, the advantage calculation, and the overall reward to ensure all pieces of the system are working well.
Reward Metrics#
These are metrics that focus on the reward itself.
Average Reward#
What it is: In each episode, GRPO generates a batch of completions. This metric is the average of the external rewards for that entire batch.
Why we track it: This is the primary indicator of the agent’s performance on the actual task, before any penalties. An increasing average reward signals that the agent is generating better completions.
What to look for: A steady, upward trend. High volatility or a downward trend can indicate instability or a poor reward signal.
Rolling Average Reward#
What it is: A moving average of the
Average Rewardover a window of the last N episodes.Why we track it: The
Average Rewardcan be noisy from one episode to the next. The rolling average smooths out this noise, making the underlying performance trend much clearer.What to look for: A clear upward trend, which confirms that the model is consistently improving over time.
Policy Stability & Loss Metrics#
These metrics diagnose the stability of the learning process and prevent the policy from changing too drastically, which can lead to training collapse.
Policy Loss#
What it is: The objective is to increase the log-probability of completions that have a high advantage. The loss is therefore the negative of the advantage multiplied by the sequence’s log-probability. Minimizing this loss encourages updates towards high-advantage actions.
Why we track it: It directly tells us if the policy is successfully learning from the advantage estimates. It’s a key indicator for diagnosing instability in the update step.
What to look for:
A generally decreasing trend: The loss should decrease as the policy gets better at producing high-reward completions.
Stability: Spikes in the policy loss can indicate that the policy is making updates that are too large and potentially unstable.
KL Divergence#
What it is: The average Kullback-Leibler (KL) divergence between the probability distribution of the trained policy and the reference policy for the generated completions.
Why we track it: This is a crucial measure for stability. It measures how much the policy is changing at each update. The
kl_betahyperparameter acts as a coefficient to penalize large KL divergences, keeping the trained policy from straying too far from the original.What to look for:
Stable, low values: This is the ideal state, showing controlled policy updates.
Exploding values: A rapid increase is a major red flag, suggesting the policy is becoming drastically different from the reference. This can lead to a “death spiral” of bad updates. If this happens, consider increasing
kl_betaor decreasing the learning rate.Vanishing values: If KL is always near zero, the policy may not be updating or exploring enough.
Total Loss#
What it is: The sum of the
Policy Lossand theKL Divergencepenalty (policy_loss + kl_beta * kl_divergence).Why we track it: This is the final value that the optimizer is trying to minimize. It shows the combined effect of trying to maximize rewards while staying close to the reference policy.
What to look for: A steady, downward trend.
GRPO-Specific Metrics#
Average Advantage#
What it is: The advantage in GRPO is calculated by normalizing the reward of each completion within its batch:
(reward - mean_batch_reward) / std_dev_batch_reward. This metric is the average of those advantages across the batch.Why we track it: The advantage is the core signal GRPO uses for policy updates. It indicates how much better or worse a completion was relative to its peers in the same batch.
What to look for: The average advantage should hover around zero. A significant deviation might suggest issues with reward normalization or batch composition, although this is less common. The key is that individual advantages are what drive the updates for specific completions.
Diagnostic Plots#
With the metrics defined we can plot them for our training. Most are noisy, so we can focus largely on the averages plot showing reward going up indicating general training.
show(generate_grpo_metrics_grid(grpo_batch_outputs))
for o in grpo_batch_outputs[20].grpo_outputs:
print(o.sampling_output.completion)
print(o.advantage)
applesE
0.0
sodbf ichescesE
0.0
cookiesE
0.0
ice creuweamE
0.0
grpo_batch_outputs[76].policy_loss
0.0
Load An Earlier Checkpoint#
We also can load an earlier checkpoint to see what the completions looked liked. In this case it seems were already close getting more pizza completions, but not as many as our final checkpoint.
As an exercise keep training going to see what happens.
filepath = "temp/grpo/pizza/grpo_checkpoint_episode_100.pt"
policy_step_100, _, _ = load_grpo_checkpoint(filepath)
2025-11-26 04:45:51,343 - INFO - Loaded GRPO checkpoint from temp/grpo/pizza/grpo_checkpoint_episode_100.pt, at episode 100
for _ in range(20):
final_output = policy_step_100.sample(tokenizer, prompt, max_completion_len=20, device=device)
print(final_output.text)
ravin likes pizzaE
ravin likes atuE
ravin likes pizzaE
ravin likes pkesodonutsE
ravin likes pdonutsE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzattxE
ravin likes piladE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes pizzaE
ravin likes lettuceE
ravin likes plesodaE
ravin likes pizzaE
ravin likes sodaE
ravin likes pizzaE
pizza_bool = []
prompt = "ravin likes "
for _ in range(100):
final_output = policy_step_100.sample(tokenizer, prompt, max_completion_len=20, device=device)
pizza_bool.append("pizza" in final_output.text)
torch.tensor(pizza_bool, dtype=torch.float).mean()
tensor(0.7500)
Suggested Prompts#
What are the benefits for GRPO over PPO for LLM training? What are the challenges?
Why did GRPO become so popular recently?
References#
DeepSeek Math Paper - Contains the GRPO examples from above.
HuggingFace explanation of GRPO - Compares PPO and GRPO as well.