
Fine-Tuning Overview#
TLDR
This a fine tuning overview
For an example with code see the Tuning in 5, 15, 50 Minutes guide.
Fine-tuning is a process where a model’s weights are updated in specific ways.
Some reasons to fine-tune include:
Specialization for specific tasks like coding.
Increasing model safety.
Improving instructability.
Giving the model its own identity.
There are numerous ways to fine-tune a model
In modern LLM development, more than one method is often used.
Cost and time are key considerations.
For computational considerations, the number of parameters being updated is a key decision.
For human input, time and cost for expertise and ratings are important.
Why Fine-Tune?#
Fine-tuning is what creates the models that most users want to use. These days, pretrained models are not the models people think of when they hear LLM or AI. Heavily fine-tuned models like ChatGPT, Bard, or Claude are what come to mind.
That’s often because pretrained models:
Don’t follow instructions well
Quite readily emit toxic content
Might perform poorly on tasks you really care about, like coding
Don’t have their own name, identity, and personality, which is important for branding and differentiation
Here’s an example of the LLAMA2 pretrained model versus the fine-tuned model on the same prompt. Note the difference in the response and the usefulness of the fine-tuned response versus the pretrained model.
You can think of a pretrained model like a half-built car with no bodywork, safety systems, or steering wheel. You have all the basics of what makes a car “go,” such as the engine, suspension, chassis. Technically this is all you need to start moving. But it’s uncomfortable to drive, dangerous as there are no safety systems added, and it lacks the styling that differentiates it from any other car.

Fig. 4 A pretrained LLM on the left (minus the steering wheel), a fine-tuned LLM on the right#
Why learn finetuning?#
In my opinion if you are looking for a job in the AI space and can only pick between learning pretraining and finetuning, I’d suggest learning finetuning. As a process finetuning many many many more times than pretraing, and by a wider group of people. Sticking with the car analogy you can think of it this way. There are only a handful of companies in the world that produce cars from scratch. That is from the ground up thinking through engine design, suspension, electronics. There are many more organizations that take existing cars and specialize them for a purpose. Think race cars, police cars, or even minor changes like repainting or changing out the stereo.
It’s the same with models. 10 or so companies produce high quality models, There are tens of thousands
Even within those companies producing top quality models, like Meta, fine tuning happens many more times than pretraining. Meta explains this in their LLAMA 2 paper, where finetuning occurs 10+ times over three different model variants (Chat/Instructioned tuned, and two rewards models), over 4 parameter sizes (70b, 30, 13b and 7b). Contrast this to pretraining which only occurs once.
Fine-Tuning Fundamentals#
Fine-tuning specifically refers to modifying the model’s weights to elicit the type of responses we want from the model. Just like pretraining, and all statistical model training, the procedure is as follows:
A model generates an output.
A measure of how “wrong” the answer is, is calculated.
Weights are updated accordingly.
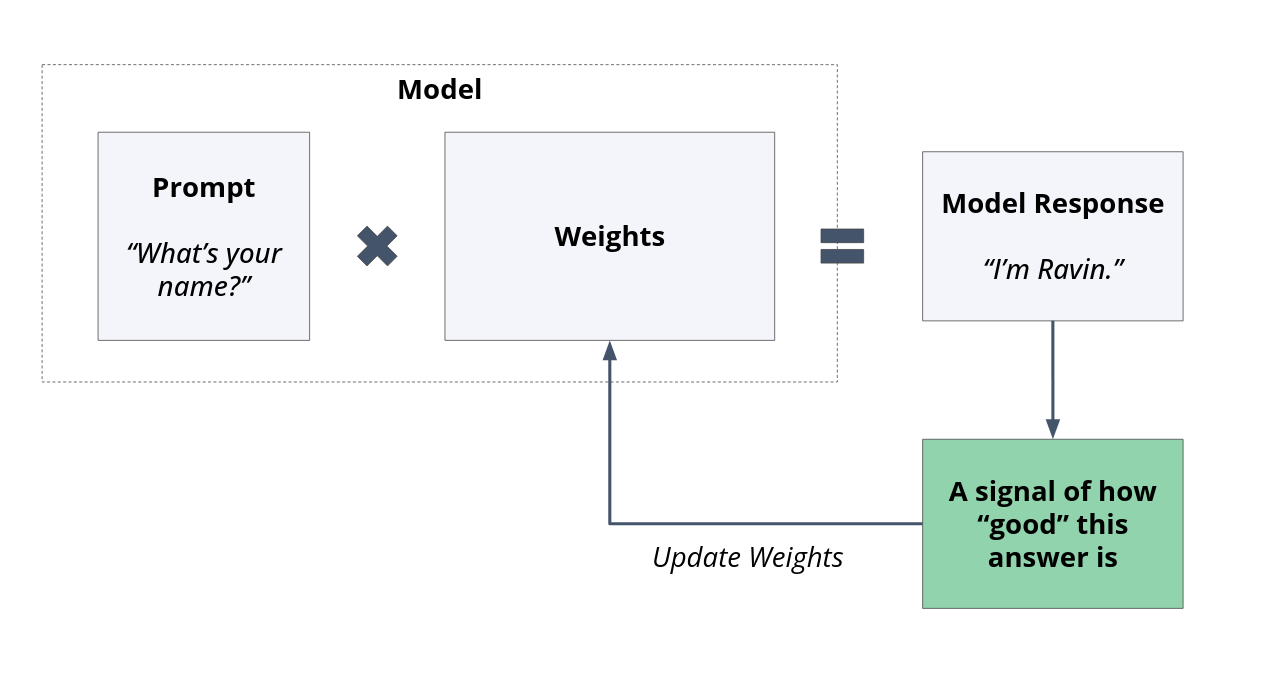
Fig. 5 How all fine-tuning methods work#
The difference lies in the fact that, instead of creating examples through self-supervision and calculating loss on the next token in pretraining, fine-tuning tends to use different training example creation methods and full responses from the model. Fine-tuning is typically applied to a pretrained model, though fine-tuned models can themselves be further fine-tuned. For example, the LLAMA 2 developers started with a pretrained model, but then fine-tuned their model through 5 iterations using multiple techniques, sometimes employing different techniques in different iterations.
Fine-tuning is not just one method but an entire class of methods. The specific one used depends on numerous factors. Common considerations include:
How different do we want the output to be
How much compute can we afford
How much human expertise can we afford
How much time do we have to wait for fine-tuning to complete
How reusable do we want our fine-tuning investment to be
How complex is the implementation
Fine-Tuning Methodologies#
Below is a list of common fine-tuning methodologies used in practice. Due to the sheer amount of written content on fine-tuning, references for each method are inline with each section.
Know that fine-tuning is a very active field, both in terms of fundamental research and empirical experimentation. Expect the methods here to rise and fall in favor, and new methods to be discovered soon.
Supervised Fine-Tuning#
For people coming from a machine learning background, Supervised Fine-tuning will feel familiar. A “training set” of prompt and output response pairs is created. The model is then prompted with the training prompt, and the “predicted” response is compared. The corresponding loss is used to update the model weights.
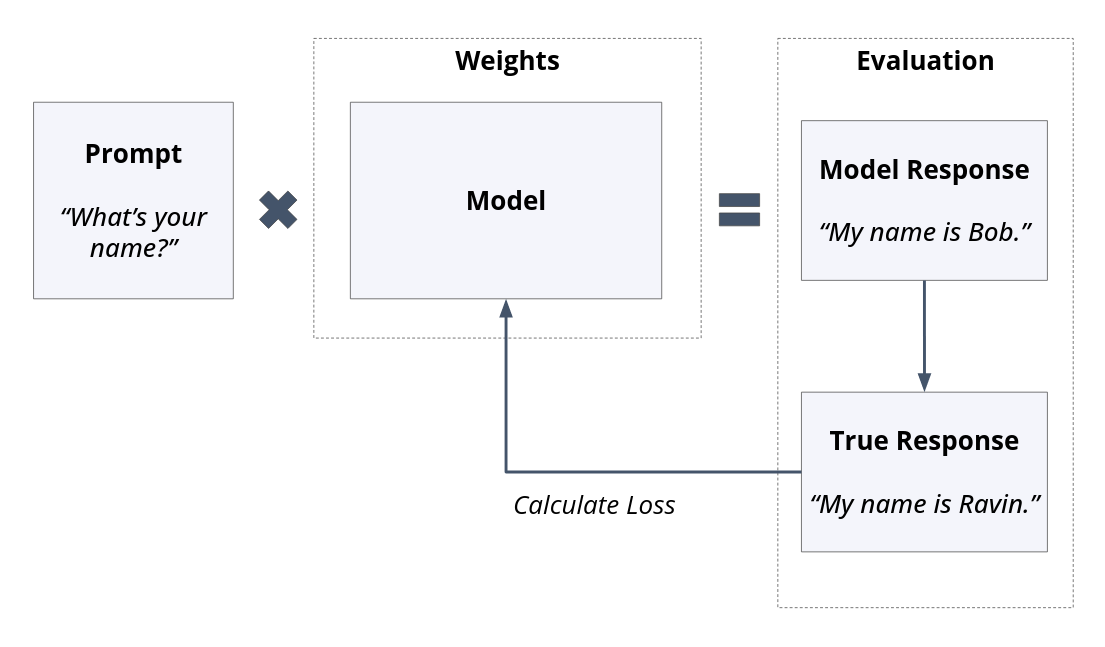
Fig. 6 In Supervised Tuning a prompt and a “true” response pair is used calculate the loss for weight updates#
The prompt and response pairs are constructed manually, and the loss is typically calculated over the entire output phrase. The weights are updated and another training loop is performed.
The benefits of supervised fine-tuning:
The intended outcome is clear and specifically trained. For instance, giving a model is most straightforward with supervised examples.
Datasets can be captured and shared. Some are publicly available.
From my experience, it seems to be the most used fine-tuning technique for the “home-built” LLM.
The downsides of creating supervised fine-tuning data are:
It’s expensive.
It requires a lot of human time.
It’s capped by human ability. High-quality examples tend to cost more.
It doesn’t provide flexibility for different generations that may be equally good.
Supervised Fine-Tuning References#
LLAMA 2 Paper - Specifically, Section 3 and Table 5. There is also a brief discussion on why human-generated SFT is not a strategy that the LLAMA team is particularly excited about, noting that they can likely replace human SFT examples entirely with AI-generated ones in the near future.
Wizard LM Fine Tuning Dataset - An open dataset of 70,000 SFT examples
Undoing Fine Tuning with more Fine Tuning - An end-to-end example explaining why companies fine-tune, why people may want to undo that fine-tuning, and then the scripts and data used to do so.
Hugging Face SFT Trainer - A well-documented and feature-rich SFT library. Even if you’re not planning to fine-tune any models yourself, reading the code will reveal exactly what is happening in SFT.
Reinforcement Learning with Human feedback#
RLHF is currently one of the most popular fine-tuning methods. The core idea behind RLHF is “Instead of humans telling the model what to say, what if humans indicated what they prefer?” To implement RLHF, The model is prompted and one or more responses are generated. Users then provide their preference to be used for model reweighting.
There are two patterns: Single-sided, where only one model output is rated,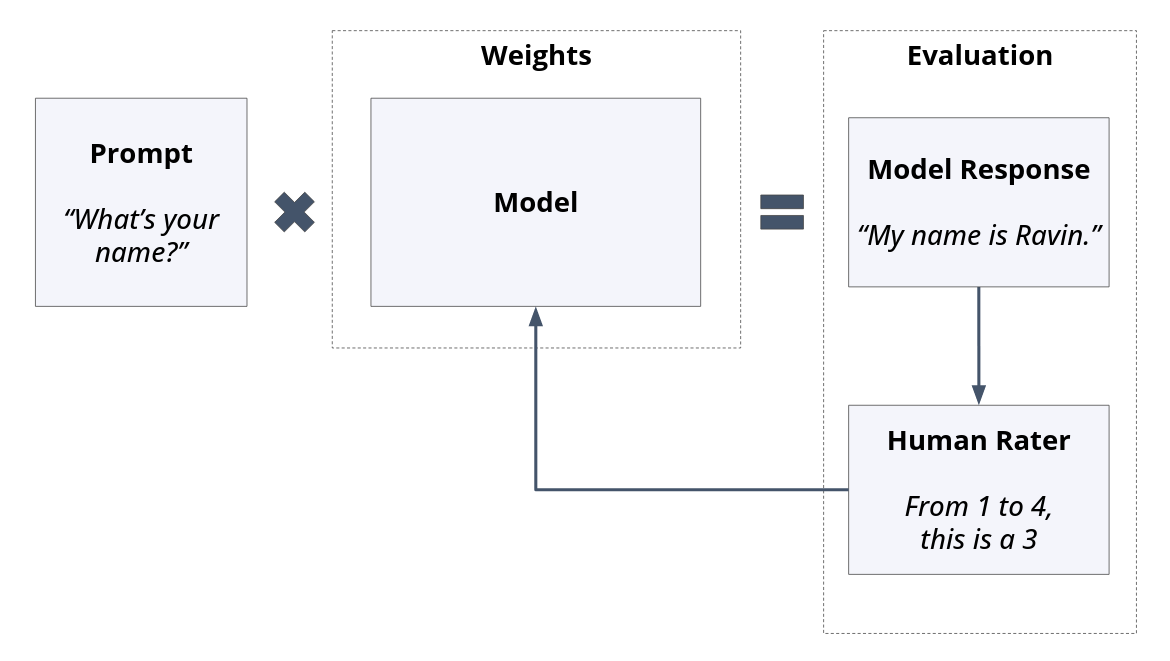
Fig. 7 In a single-sided setup, raters rate a single response.#
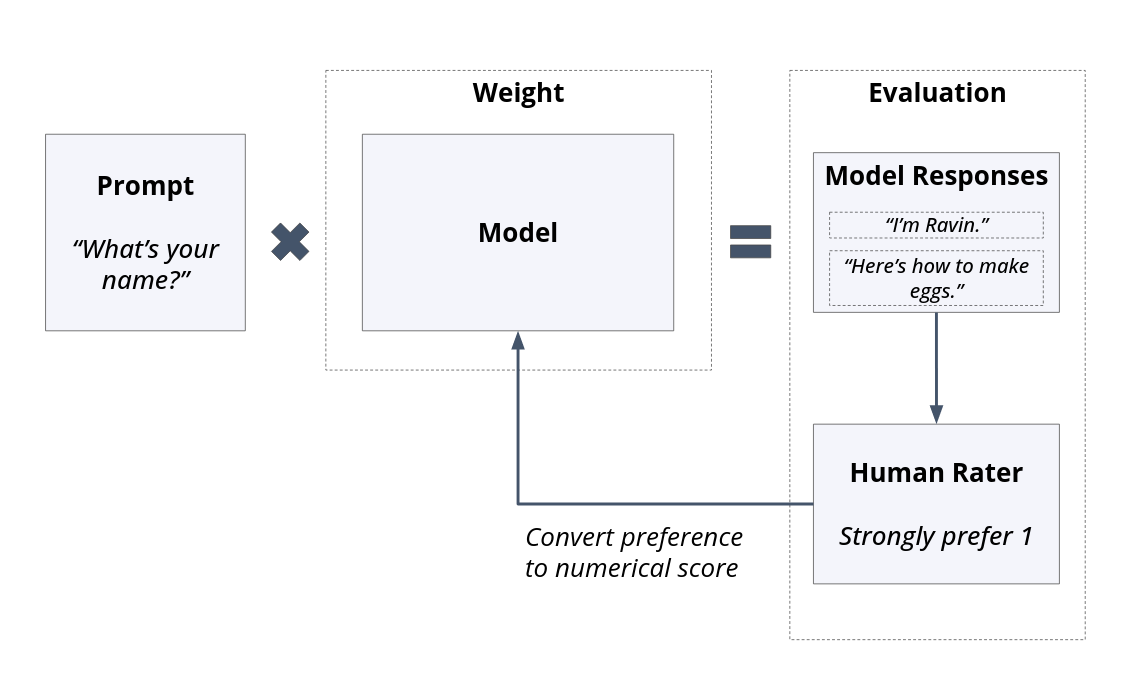
Fig. 8 In a side-by-side setup, raters choose between two or more different versions.#
The benefits of RLHF are:
Collecting preferences is easier and faster for humans than writing prompts.
Models may be able to surpass the writing abilities of raters, thereby increasing the fine-tuning quality ceiling.
The model responses aren’t overly constrained to single patterns.
Multiple model outputs can be compared simultaneously.
For some unknown reason, RLHF works really well.
The downsides for RLHF are
It can require many ratings, usually thousands, up to millions or more.
Getting a large volume of ratings typically requires some software infrastructure
RLHF References#
Anthropic Red Teaming - Figure 3 shows a rating interface and Section 3.2 discusses how it was used in model training.
InstructGPT - This is a frequently cited paper from OpenAI that strongly establishes RLHF as part of their strategy. It was released pre-ChatGPT and (in my own words) can be considered the precursor to ChatGPT.
LLAMA 2 Paper - RLHF is extensively used for LLAMA 2 fine-tuning. Section 3.2 contains all the details, including the amount of data collected and the preference ranking scheme.
RLHF Shortcomings - This focuses on RLHF itself, rather than a model. It discusses some of the challenges with the technique and provides a balanced perspective.
Reward Models#
Reward models are models that rank the outputs of user models that are being trained. With multiple models, it can be easy to mix them up. From this point, we’ll make this distinction:
User model - Models that will be shipped to users
Reward Model - Models trained specifically to provide rewards to other models
Reward models can be created in various ways and essentially are fine-tuned models in their own right. For example, RLHF is often used to train the reward model, with the idea that human preferences can be learned and then reused in automated training tools. For GPT-4 training, OpenAI configured GPT-4 instances into rule-based reward models. These rule-based models used multiple sources of information (prompts, outputs from a policy model, and a human rule) to calculate the score for the GPT-4 user model output.
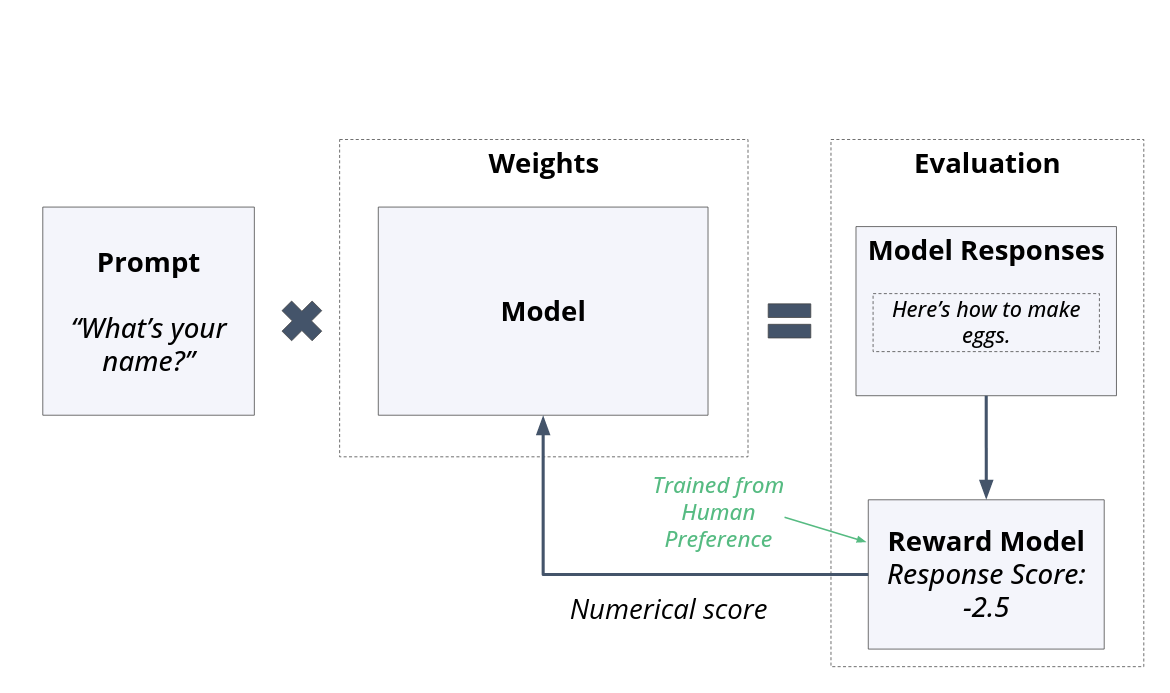
Fig. 9 A model provides a preference score. This is a single-sided example. Models that can rank side-by-side examples also exist.#
The reward model is often a copy of the pretrained model, which is fine-tuned specifically for reward scoring. One distinct difference is that the token prediction head from the pretrained model is replaced with a regression head that outputs ratings. This doesn’t necessarily need to be the case, though in my reading so far, it seems that for the largest model training at companies like Meta and OpenAI, there is a benefit for the reward model being the same parameter size as the user model it is fine-tuning.
The benefits of reward models are:
They scale well and have been proven to be effective.
They reduce the need for humans to provide preferences by reusing known preference knowledge.
They provide an additional numerical signal to assess user model outputs.
This signal can be used to measure training progress in the fine-tuning stage.
The downsides:
They are now another model that needs to be considered for training, checkpointing, evaluating, computing, etc.
Reward modeling is enveloped in more secrecy and less is published about them, making it difficult to replicate the results from major AI firms.
They are usually not open-sourced, even when the fine-tuned model weights are open-sourced.
For instance, the LLAMA 2 reward model’s weights were not released, even though the final model was made available.
They introduce an additional step that could potentially cause issues in the training process.
Reward Model References#
Hugging Face Reward Trainer - An open-source implementation of a reward model trainer. The documentation includes an example trained from the open-source RLHF dataset from Anthropic.
LLAMA 2 Paper - Reward modeling is extensively used in the LLAMA 2 training. Section 3.2.1 details their use. Table 38 shows the output of two reward models on a fixed prompt with different outputs. Notably, while the user model weights were open-sourced, the reward model weights were not.
Deepmind Sparrow Paper - Section 2.5 and AppendiX D go into specific details.
GPT-4 Technical Paper The section titled Model-Assisted Safety Pipeline.
Constitutional AI#
Constitutional AI is a method developed by Anthropic to reduce human harm and further scale AI preference training. The basic idea is, instead of needing humans to specifically provide a preference between output prompts, models can be provided with a constitution of values, from which they can self learn what appropriate responses are. The novel idea here is that the model(s) critique, rewrite responses, and train themselves based on a small constitution provided by humans. The constitutional AI training process itself has many steps, and involves more than 5 models.

Fig. 10 The multi-step constitutional AI training process#
The benefits of this more complex process are:
Writing a small set of principles is a less daunting task than rating thousands of responses.
Humans are exposed to fewer harms during the training process.
The training process is more scalable.
In practice, Anthropic demonstrates that this method is effective through their assessment, and puts it into practice with their own AI Agent Claude. The key question here then largely falls on writing the constitution itself. Anthropic has experimented with a number of ways to do so.
Constitutional AI references#
Constitutional AI Paper - Original publication with a link to the full paper.
Collective Constitution Blog Post - An effort to create a constitution that includes a broader audience.
Constitution Examples - This shows the constitution and some of the model responses and revisions.
Parameter Efficient Fine Tuning (PEFT)#
As models become larger, updating the weights becomes more computationally and economically challenging. However, a simple trick to mitigate this is by not updating the weights, or at least not all of them. Similar to fine-tuning, there are numerous strategies being developed and tested for this methodology. These methods are particularly appealing to open source or “home” LLM builders as they enable significant changes in model behavior with relatively minimal cost and effort. Like fine-tuning, there are many methods and more are emerging each day. We’ll cover the two that have been most widely used, with links to other methods.
Hugging Face’s PEFT Library. - 11+ fine-tuning versions implemented in code.
Parameter Efficient Prompt Tuning Paper - The original paper that introduced the name and the idea. In particular Figure 1 shows the performance and Figure 2 shows the architecture.
Prompt Tuning#
In any prompted LLM response, there are two things that affect the output more than any other factor:
The model weights
The prompt
Given this, the idea of prompt tuning is to add a new set of weights between the prompt and the model, and only tune those. In the paper introducing this method, the T5 model weights were 11,000,000,000 parameters, and the added prompt weights were 20,400 parameters. Yet, the research showed similar performance with prompt tuning to full model weight fine-tuning on a benchmark dataset.
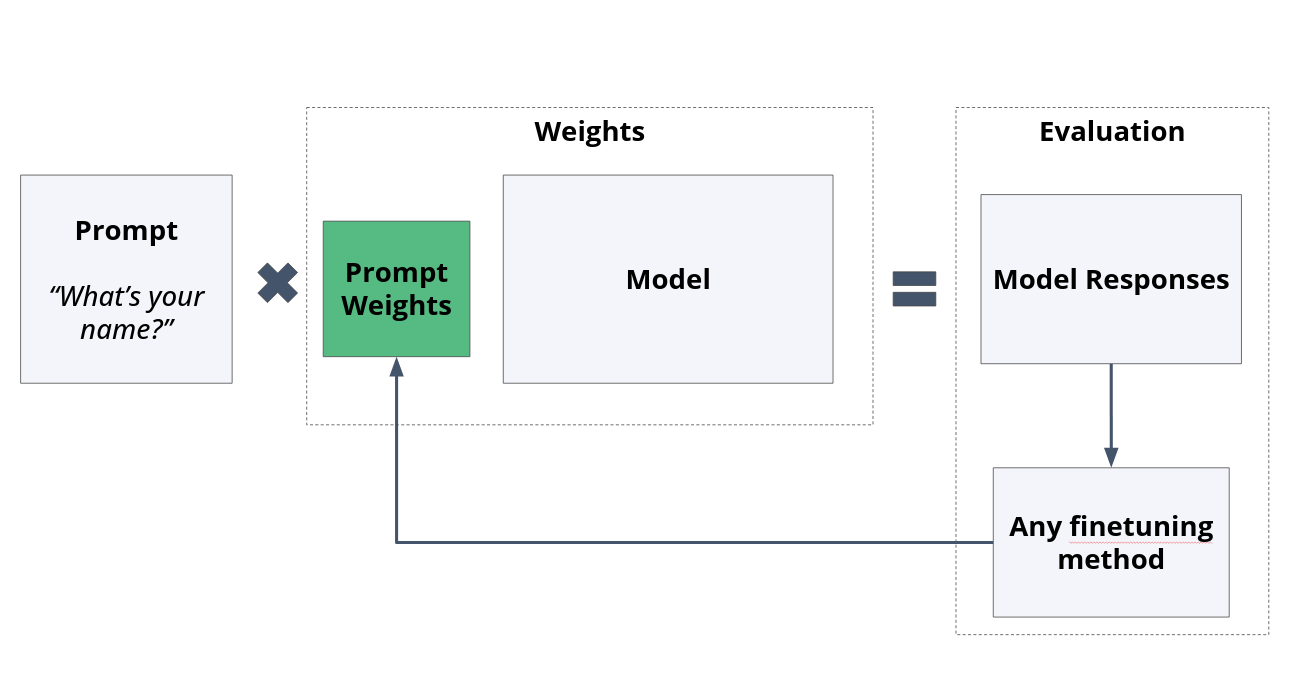
Fig. 11 The original model weights stay untouched, a smaller amount of weights are introduced and tuned.#
Prompt Engineering#
Prompt Engineering, or prompt design, or system prompts are similar ideas. The model is prompted to “act like a pirate” or “be a math expert”. This method is quite popular and accessible because of how intuitive and easy it is; any user can adjust the behavior as part of their prompt. It’s also quite effective, changing the output generation dramatically. It’s so effective that deployed models like ChatGPT have a pre-prompt that is hidden from the user but often exposed through clever prompting. However, this isn’t categorized as fine-tuning because no weights are updated.
The benefits of this method are its ease for anyone to update or generate as these are written in natural language. It doesn’t require any additional compute at train time, which also makes them easy to iterate upon. The downsides are that they take up portions of the context window and compute at inference time, and that they “wear off” as they don’t affect behavior as strongly as fine-tuning.
For examples, refer to Anthropic’s red teaming paper and the LLAMA 2 Paper. Anthropic’s red teaming paper showed how prompt tuning basically made a model no safer than a baseline pretrained model. In LLAMA 2, Meta also showed how prompt tuning can fail quite readily, so much so that they invented a new fine-tuning method called Ghost Attention to make fine-tuning more effective.
Prompt Tuning References#
Blog post on Prompt Tuning - A nice overview, with a deeper dive into hard and soft prompt tuning.
Hugging Face Prompt Tuning Guide - More specific examples with comparisons to other methods like prefix tuning and p tuning.
Low-Rank Adaptation of Large Language Models#
LORA, as abbreviated, is a technique that reduces the number of parameters that need to be trained by reducing the dimensionality using a linear algebra technique called Singular Value Decomposition, also known as Rank Decomposition.
A full explanation would require a course in linear algebra, but here are two pieces of intuition:
The first piece of insightful explanation comes from an LLM:
Dimensionality Reduction: Singular values can be used to reduce the dimensionality of data by projecting the data onto a lower-dimensional subspace. This technique is useful in machine learning and data analysis, where high-dimensional data can be simplified for efficient processing and analysis.
The other is by seeing a basic example. Consider these two matrices:
matrix_1 = [[1, 2],
[3, 6]]
matrix_2 = [[1, 2],
[3, 5]]
In matrix_1, the second row is a linear combination of the first row.
Specifically, if you multiply [1,2] by three, you get the second row.
In this case, matrix_1 has a rank of 1.
This means the second row provides no additional information.
Contrast this with matrix_2, where no linear multiplication of either row will yield the first.
In this case, matrix_2 has a rank of 2.
You can verify this yourself with numpy:
f"Rank matrix_1 {np.linalg.matrix_rank(matrix_1)}"
f"Rank matrix_2 {np.linalg.matrix_rank(matrix_2)}"
Rank matrix_1 1
Rank matrix_2 2
Now, this is an oversimplified example that’s leaving out a lot of the fundamental details.
Try running U, S, Vh = np.linalg.svd(matrix_1) or reading the docs for the svd method and you’ll see how much deeper this topic goes.
However, even without the specific details, the dimensionality reduction intuition is the same idea with 11 billion parameter LLMs. The pretrained model’s parameters are in a super high dimensional space, but for fine-tuning, you likely can fine-tune many fewer parameters in a compressed space and influence the final output behavior drastically. The trick the authors use is creating a new set of LORA parameters that are much smaller than the others, but are shaped in a way that can be easily combined without changing the input and output sizes of certain parts of the model.
Here’s a visualization,
adapted from the original paper,
where A and B are the LORA parameters.
The dimension x is the original input dimension and r is the reduced dimension:
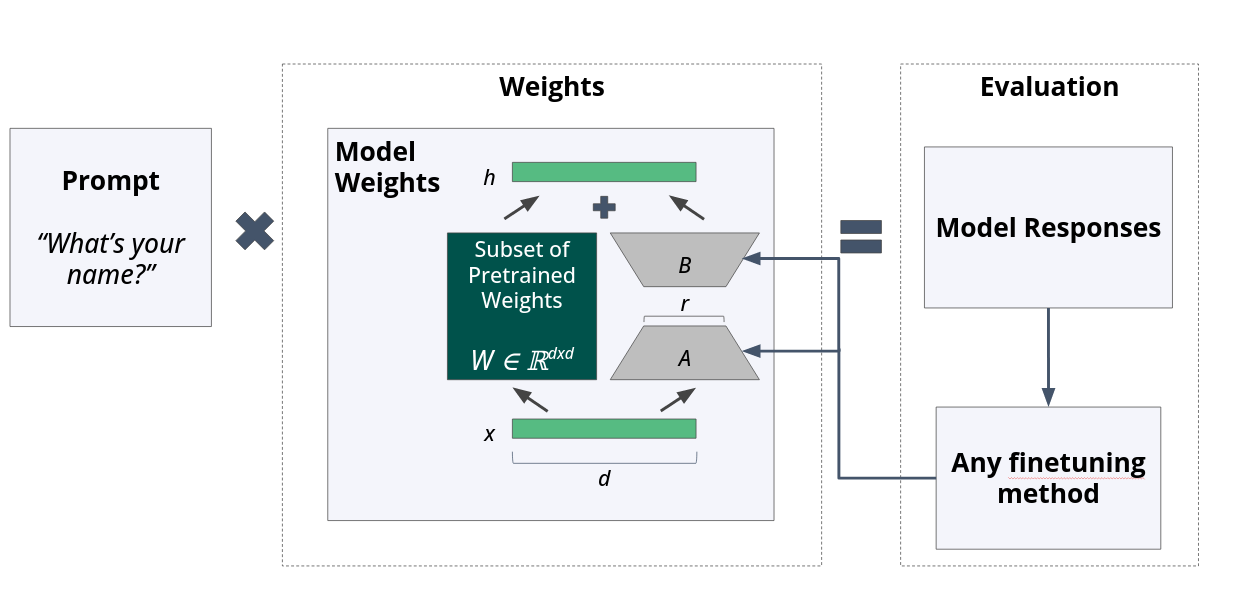
Fig. 12 An adapted diagram from the original LORA paper. A and B are the weights added to the LLM system trained. Within a pretrained LLM that subset may only map to subset of the original models.#
Aside from the mathematical properties, LORA has a number of impressive engineering properties. Apart from fine-tuning efficiency, LORA weights can be swapped in and out for different tasks for the same user, or different LORA weights can be stored as different model implementations for different users. LORA methods are also actively being improved with advancements like Qlora and DyLORA, which provide improvements upon the original.
LORA References#
The original LORA paper - Contains all the details for a method. It was written in 2021 and ends with advice for future extensions, which you can directly see in the subsequent papers.
Hugging Face Guide to LORA - A good summary of the LORA method and HF library.
Google Cloud LORA Implementation - Contains advice on LORA methods, when to use them and how much memory and processing is saved by various LORA methods.
Databricks guide to LORA Finetuning - A longer guide on LORA with some code implementations.
Stanford Lecture on LORA - A very well written educational document on SVD that is covers the theory and mathematical details quite nicely.
LORA from scratch - A tutorial showing LORA implemented as PyTorch layers.
Fine Tuning Mistral 7b in Colab - A end to end guide with code.
Distillation#
Important
This section is in reference status
Distillation is taking a outputs from one model or generation and using that to finetune a model. Either the same one or a different one
Context Distillation - Prompt a model with a context, such as, “Make your models more verbose”,
Knowledge Distillation - Take a big model, have it “teach” a smaller model
Context Distillation - Prompting the model with a prompt prefix, such as “talk like a pirate”, and then training on the result. This will save tokens during inference, but ideally retain the learned behavior.
Knowledge Distillation - A paper showing how larger models can be used to train smaller models.