
GPT from “scratch” in Flax#
TLDR:
This single notebook contains a full GPT that you can train at home.
It’s a reimplementation of Andrej Karpathy’s GPT from Scratch from PyTorch into Jax/Flax.
The things to pay attention to are:
The tokenizer
The model structure and definition
How the model performance changes over various checkpoints
The trained model and the initial model#
Before we dive in, here’s the final model. It was trained on the Tiny Shakespeare dataset.
# A sample generation
idx = bglm.apply(state.params, 600, method='generate')
generation = ts.decode(idx.tolist()[0])
print(generation.strip())
MENENIUS:
COMINIUS:
Why, sir, or hast been so what I did;
Respect is his, and go with holds,
And backs hangment tomb, Camillo true,
To speak no away in this son of roopiness;
Whithe that is all for you was, kind how I am
Hope for you as time our place.
LARTIUS:
Alas, only to love, to ho,
Him it with the cause to one this, bitter her
May a shepherd haze. Angelo.
But one till the officers to this true,
Thus expect us was unto the; for I am every begue;
And come unto our bild, man, then joy in his Pome.
BENVOLIO:
How down seems be my voiciant is upon himself,
And since him out of a diath. whom
And here’s where we started, a bunch of random characters.
idx = bglm.apply(initial_params, 600, method='generate')
print(ts.decode(idx.tolist()[0]).strip())
boysZBZMAhCxFaSKeNyDs,WPHVxVWLoH hus
dV,XbV
Dhwha'rJFolY;rRlhRsL;PQsih$w-jYIWO$KT iyFUhrlYT,! xHZ
gUBslha &mHcYO.KmUDaCLjGqg? eVTYSOlllqJh$?$MlSTwj;jAACkPMNsJ-;!NCzrIhgiSwkb;M!VrQLQ:?gN.m:vNFlVf&OK,X-ygBaXYLkxWSu:o3fkrxBd;y:CMQHRuZWbs
VA,jkUuYzq::xXOeCst;qjLLdEKAAZHOU?:pmnzp:rEZRI&v&lPjJ,BVbmc N:wxAZ$AX-LnawOzE; GoyDOHg&xSuFCKTTkwJCxTMh:oFo,&3?izWwD wh!yEVokSP.qesfhfoIV!&.cwmL:KbRofnrdmXDETA'-'GWPURTzwX.ubveT.XMHY;f-wmz:-EqBHFab;gfJVJL-XIQe'WdCc$nguDpF3pTsB:3jI.bCKvYlJPCRCp,o?3atqGI.NPjRbkvBSex,QPdIekjhx! MUjbSYor:BcDDkff&HcbQN,gkv3BvNMdr-kddiRmubfc.XEGsImf'uqqZJqrLzCAgsUKVQnU$xpAgTVbalnVbKUpM
The rest of this notebook shows how we get from our random initial LLM to our trained one.
Why Flax and Jax#
Similar to PyTorch, Flax and Jax are production-grade tools that are used from individual research to massive multi-cluster LLMs.
For this guidebook, there are some additional reasons:
I find that the separation of state, model definition, and training loops in Flax make it easier to disambiguate the concepts.
Being able to print the layer outputs as well helped with understanding and debugging.
Deterministic by default makes debugging simpler.
Now you have both a PyTorch and Flax/Jax reference!
This notebook dives straight into a neural network model. If you need a primer on Neural Networks, start with NN Quickstart.
Additional Notes#
Here are some additional details for easy reference:
B, T, C Meaning#
Karpathy uses the shorthand symbols B, T, C in his code and videos. He explains their meanings here, which I’ll write out for easy reference:
B - Batch - How many training examples we’re using at once. This is just for computational efficiency.
T - Time - In a text input array, either encoded or decoded, the index that is being referenced.
C - Channel - The specific token “number”, or index in the embedding array. This matches the…
Block Size is Context Window#
The length of the input sequence the model gets for making the next character prediction.
Suggested Exercises#
For additional hands-on learning, I’ve included two additional datasets here, along with all the code for training and text generation.
abcdef A quick brown fox jumped over the lazy dog
These strings have specific properties. The first has no repeating characters, and it’s easy to encode and decode to integers in your head. This means it’s easy to get an overfit model with perfect predictions for debugging, as well as inspecting the parameters. The second has no repeating alphabetic characters, but it does have spaces, adding just one additional layer of complexity.
For additional debugging and understanding, you can perform an ablation study. That means removing parts of the model, making certain parameters smaller or larger, and seeing what happens. Visualize parts of the learned parameters using heatmaps and other tools to see what the model is learning.
qb = QuickBrownFox(block_size = block_size, batch_size=batch_size)
ab = Alphabet(block_size = block_size, batch_size=batch_size)
Imports#
!pip install flax==0.7.5 jax==0.4.24 optax
import logging
import requests
from typing import Sequence
import matplotlib.pyplot as plt
import numpy as np
from tqdm.auto import tqdm
import jax
import jax.numpy as jnp
import flax
from flax import linen as nn
from flax.training import train_state, checkpoints
import optax
SEED = 1337
def create_logger():
"""
Create and configure a logger for notebook use with a console handler.
Returns:
logging.Logger: Configured logger with a console handler.
"""
logger = logging.getLogger("notebook")
logger.setLevel(logging.INFO)
if not logger.hasHandlers():
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(levelname)s - %(message)s")
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
return logger
logger = create_logger()
WARNING:absl:Type handler registry overriding type "<class 'float'>" collision on scalar
WARNING:absl:Type handler registry overriding type "<class 'bytes'>" collision on scalar
WARNING:absl:Type handler registry overriding type "<class 'numpy.number'>" collision on scalar
WARNING:absl:Type handler registry overriding type "<class 'bytes'>" collision on scalar
WARNING:absl:Type handler registry overriding type "<class 'numpy.number'>" collision on scalar
WARNING:absl:Tensorflow library not found, tensorflow.io.gfile operations will use native shim calls. GCS paths (i.e. 'gs://...') cannot be accessed.
# Checking if Cuda is loaded
devices = jax.devices()
print(devices)
[CpuDevice(id=0)]
Data Loaders#
This text-based class implements the tokenizer, as well as the string encoder and decoder. This is not to be confused with the encoder and decoder portions of a Transformer, which are different things.
import abc
class BaseTextProcessor:
"""
Base class for text processing which includes methods to encode, decode,
and split text data for training and testing.
Attributes:
block_size (int): Size of a block of text to process.
batch_size (int): Number of text blocks in a batch.
"""
def __init__(self, block_size: int, batch_size: int):
"""
Initializes the text processor with block size and batch size.
Parameters:
block_size (int): The size of a block of text.
batch_size (int): The number of text blocks in each batch.
"""
self.block_size = block_size
self.batch_size = batch_size
self._data = None
self.text = self.set_text()
self.chars = sorted(list(set(self.text)))
self.vocab_size = len(self.chars)
self.stoi = {ch: i for i, ch in enumerate(self.chars)}
self.itos = {i: ch for i, ch in enumerate(self.chars)}
@abc.abstractmethod
def set_text(self) -> str:
"""
Abstract method to set the text corpus to be used by the processor.
Returns:
str: The text corpus.
"""
pass
def encode(self, input_string: str) -> list:
"""
Encodes the input string into its integer representation.
Parameters:
input_string (str): The string to encode.
Returns:
list: List of integers representing the encoded string.
"""
return [self.stoi[c] for c in input_string]
def decode(self, token_iter: iter) -> str:
"""
Decodes a list of tokens into the corresponding string.
Parameters:
token_iter (iter): An iterable of integer tokens to decode.
Returns:
str: The decoded string.
"""
return "".join([self.itos[int(c)] for c in token_iter])
def batch_decoder(self, tokens_lists: list) -> list:
"""
Decodes a list of token lists to their corresponding strings.
Parameters:
tokens_lists (list): A list of lists containing tokenized data.
Returns:
list: A list of decoded strings.
"""
return [self.decode(tokens) for tokens in tokens_lists]
@property
def data(self):
"""
Lazily encodes the text data and returns it. Ensures data is only encoded once.
Returns:
jnp.array: The encoded data as a JAX array.
"""
if self._data is None:
self._data = jnp.array(self.encode(self.text))
return self._data
def train_test_split(self, split: float = 0.9):
"""
Splits the data into training and validation sets.
Parameters:
split (float): Fraction of data to be used as training data.
Returns:
tuple: A tuple containing the training data and validation data.
"""
n = int(split * len(self.data))
train_data = self.data[:n]
val_data = self.data[n:]
return train_data, val_data
def get_batch(self, key):
"""
Generates a batch of training examples.
Parameters:
key: JAX PRNG key for random number generation.
Returns:
tuple: A tuple containing the input examples (x), the target array (y),
and the indices (ix) of the starting positions in the data.
"""
ix = jax.random.randint(key=key, minval=0, maxval=len(self.data) - self.block_size,
shape=(self.batch_size,))
x = jnp.stack([self.data[i:i + self.block_size] for i in ix])
y = jnp.stack([self.data[i + 1:i + self.block_size + 1] for i in ix])
return x, y, ix
Three datasets are included:
Tiny Shakespeare - This is the original from the tutorial.
Alphabet - Just the alphabet, no character repeats so the LLM should be able to memorize the next token.
QuickBrownFox - A sentence where letters don’t repeat, but spaces do, leading to a tiny bit of variability.
The second two datasets are included for debugging purposes. One of the easiest ways to debug an LLM, or any deep learning model, is to overfit a simple dataset. If your model can’t do that, you have problems.
class TinyShakespeare(BaseTextProcessor):
"""
Processor for handling text data from the Tiny Shakespeare dataset.
Inherits from BaseTextProcessor.
"""
def set_text(self) -> str:
"""
Fetches and sets the text data from the Tiny Shakespeare dataset.
Returns:
str: The text data fetched from the dataset.
"""
text = requests.get(
"https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt"
).text
return text
class QuickBrownFox(BaseTextProcessor):
"""
Processor for handling a predefined text string.
Inherits from BaseTextProcessor.
"""
def set_text(self) -> str:
"""
Sets a predefined text string for processing.
Returns:
str: A preset text.
"""
return "The quick brown fox jumped over the lazy dog"
class Alphabet(BaseTextProcessor):
"""
Processor for handling a simple alphabet string.
Inherits from BaseTextProcessor.
"""
def set_text(self) -> str:
"""
Sets a simple alphabet string for processing.
Returns:
str: A simple alphabet string.
"""
return "abcdefg"
Random Keys#
JAX, on which Flax is based, by design requires explicit keys for its randomness. This is counterintuitive but smart for many reasons. Read the docs to learn more.
# Initialize the random number generator
ROOT_KEY = jax.random.PRNGKey(seed=0)
# Split the root key into three separate keys
MAIN_KEY, PARAMS_KEY, DROPOUT_KEY = jax.random.split(ROOT_KEY, num=3)
Model Constants#
BATCH_SIZE = 128 # Number of independent sequences processed in parallel
BLOCK_SIZE = 64 # Maximum context length for predictions
Load and Encode Data#
# Create an instance of TinyShakespeare with specified block size and batch size
ts = TinyShakespeare(block_size=BLOCK_SIZE, batch_size=BATCH_SIZE)
# Uncomment the appropriate line below to use a different text processor
# ts = utils.QuickBrownFox(block_size=BLOCK_SIZE, batch_size=BATCH_SIZE)
# ts = utils.Alphabet(block_size=BLOCK_SIZE, batch_size=BATCH_SIZE)
# Fetch a batch of data from the text processor
xb, yb, ix = ts.get_batch(MAIN_KEY)
# Display the first 50 characters of the text
ts.text[:50]
'First Citizen:\nBefore we proceed any further, hear'
ts.vocab_size # Display the vocabulary size
65
xb[:2] # View the first two elements of the batch
Array([[ 1, 61, 43, 43, 42, 57, 6, 1, 61, 47, 58, 46, 1, 53, 60, 43,
56, 61, 46, 43, 50, 51, 47, 52, 45, 1, 40, 56, 53, 61, 57, 6,
0, 15, 59, 50, 50, 47, 52, 45, 1, 53, 44, 1, 57, 47, 51, 54,
50, 43, 57, 11, 1, 51, 43, 39, 45, 56, 43, 1, 61, 43, 56, 43],
[ 8, 0, 14, 59, 58, 1, 39, 57, 1, 58, 46, 47, 57, 1, 58, 47,
58, 50, 43, 1, 46, 53, 52, 53, 59, 56, 57, 1, 51, 43, 1, 39,
52, 42, 1, 51, 47, 52, 43, 6, 0, 31, 53, 1, 63, 53, 59, 56,
1, 42, 47, 57, 50, 47, 49, 43, 6, 1, 58, 53, 1, 61, 46, 53]], dtype=int32)
ts.batch_decoder(xb[:2]) # Decode the first two batches for human-readable output
[' weeds, with overwhelming brows,\nCulling of simples; meagre were',
'.\nBut as this title honours me and mine,\nSo your dislike, to who']
Model Parameters#
# Model Parameters Configuration
VOCAB_SIZE = ts.vocab_size # Vocabulary size from the text processor instance
N_EMBD = 120 # Number of embedding dimensions
N_HEAD = 6 # Number of attention heads
N_LAYER = 6 # Number of transformer layers
DROPOUT_RATE = 0.4 # Dropout rate for training
# Alternative model configuration
# N_EMBD = 300
# N_HEAD = 6
# N_LAYER = 6
# DROPOUT_RATE = 0.2
global_mask = nn.make_causal_mask(xb) # Generate a causal mask
global_mask.shape # Display the shape of the global causal mask
(128, 1, 64, 64)
Multi-Head Attention#
Now, this is not from scratch, but I chose to use the pre-canned version to show what a production implementation would look like. Andrej already does a great job explaining the internals of attention, so I didn’t feel that repeating it here would add any extra value at the moment.
class MultiHeadAttention(nn.Module):
"""
A module to perform multi-head attention using Flax's linen library.
This combines multiple attention heads into a single operation.
"""
num_heads: int
n_embd: int
@nn.compact
def __call__(self, x, training):
"""
Apply multi-head attention to the input tensor.
Parameters:
x (tensor): Input tensor.
training (bool): Flag to indicate if the model is training (affects dropout).
Returns:
tensor: Output tensor after applying multi-head attention and a dense layer.
"""
x = nn.MultiHeadDotProductAttention(
num_heads=self.num_heads,
dropout_rate=DROPOUT_RATE,
deterministic=not training
)(x, mask=global_mask)
x = nn.Dense(self.n_embd)(x)
return x
Test Parameter Initialization#
# Create an instance of the MultiHeadAttention module
mha = MultiHeadAttention(
# head_size=head_size, # Uncomment and define head_size if needed
num_heads=N_HEAD,
n_embd=N_EMBD,
)
# Initialize the input tensor
input_x = jnp.ones((BATCH_SIZE, BLOCK_SIZE, N_EMBD))
logger.debug(f"Input tensor shape: {input_x.shape}")
# Initialize the parameters and apply the model
params = mha.init({'params': PARAMS_KEY, "dropout": DROPOUT_KEY}, input_x, training=True)
print(f"Output shape after applying MultiHeadAttention: {mha.apply(params, input_x, training=False).shape}")
Output shape after applying MultiHeadAttention: (128, 64, 120)
# Example of initializing and applying with a different key
input_x = jnp.ones((BATCH_SIZE, BLOCK_SIZE, N_EMBD))
params = mha.init(ROOT_KEY, input_x, training=False)
mha.apply(params, input_x, training=False)
Feedforward Layer#
(batch_size, block_size) -> (batch_size, block_size, n_embd)
class FeedForward(nn.Module):
"""
A feedforward neural network module using Flax's Linen API with two dense layers
and a dropout layer for regularization.
"""
@nn.compact
def __call__(self, x, training):
"""
Applies a sequence of layers to the input tensor.
Parameters:
x (tensor): Input tensor to the feedforward network.
training (bool): Flag to indicate if the model is training.
Returns:
tensor: The output tensor after processing through dense and dropout layers.
"""
x = nn.Sequential([
nn.Dense(4 * N_EMBD),
nn.relu,
nn.Dense(N_EMBD),
nn.Dropout(DROPOUT_RATE, deterministic=not training)
])(x)
return x
# Create an instance of the FeedForward module
ff = FeedForward()
# Prepare input tensor
input_x = jnp.ones((BATCH_SIZE, BLOCK_SIZE, N_EMBD))
logger.debug(f"Input tensor shape: {input_x.shape}")
# Initialize the model parameters and apply the model
params = ff.init({'params': PARAMS_KEY, "dropout": DROPOUT_KEY}, input_x, training=True)
print(f"Output shape after applying FeedForward: {ff.apply(params, input_x, training=False).shape}")
Output shape after applying FeedForward: (128, 64, 120)
print(ff.tabulate(ROOT_KEY, input_x, training=False,
console_kwargs={'force_terminal': False, 'force_jupyter': True}))
FeedForward Summary ┏━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ path ┃ module ┃ inputs ┃ outputs ┃ params ┃ ┡━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ │ FeedForward │ - float32[128,64,120] │ float32[128,64,120] │ │ │ │ │ - training: False │ │ │ ├──────────────┼─────────────┼───────────────────────┼─────────────────────┼──────────────────────────┤ │ Sequential_0 │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────┼─────────────┼───────────────────────┼─────────────────────┼──────────────────────────┤ │ Dense_0 │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────┼─────────────┼───────────────────────┼─────────────────────┼──────────────────────────┤ │ Dense_1 │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────┼─────────────┼───────────────────────┼─────────────────────┼──────────────────────────┤ │ Dropout_0 │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────┼─────────────┼───────────────────────┼─────────────────────┼──────────────────────────┤ │ │ │ │ Total │ 115,800 (463.2 KB) │ └──────────────┴─────────────┴───────────────────────┴─────────────────────┴──────────────────────────┘ Total Parameters: 115,800 (463.2 KB)
Block#
class Block(nn.Module):
"""
A transformer block module using Flax's linen API, which integrates multi-head attention
and feedforward neural network layers.
"""
@nn.compact
def __call__(self, x, training):
"""
Process the input tensor through the transformer block.
Parameters:
x (tensor): Input tensor.
training (bool): Whether the model is in training mode.
Returns:
dict: A dictionary containing the output tensor and the training status.
"""
# Initialize the MultiHeadAttention and FeedForward modules
sa = MultiHeadAttention(n_embd=N_EMBD, num_heads=N_HEAD)
ff = FeedForward()
# Apply self-attention and residual connection followed by layer normalization
x = x + sa(nn.LayerNorm(N_EMBD)(x), training=training)
# Apply feedforward network and residual connection followed by layer normalization
x = x + ff(nn.LayerNorm(N_EMBD)(x), training=training)
return dict(x=x, training=training)
# Instantiate the Block module
block = Block()
# Prepare the input tensor
input_x = jnp.ones((BATCH_SIZE, BLOCK_SIZE, N_EMBD))
logger.debug(f"Input tensor shape: {input_x.shape=}")
# Initialize the model parameters and apply the model
block_params = block.init({'params': PARAMS_KEY, "dropout": DROPOUT_KEY}, input_x, training=True)
logger.info(f"Output tensor shape after block application: {block.apply(block_params, input_x, training=False)['x'].shape=}")
INFO:notebook:Output tensor shape after block application: block.apply(block_params, input_x, training=False)['x'].shape=(128, 64, 120)
print(block.tabulate(ROOT_KEY, input_x, training=False,
console_kwargs={'force_terminal': True, 'force_jupyter': True},
column_kwargs={'width': 400}))
Block Summary ┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ path ┃ module ┃ inputs ┃ outputs ┃ params ┃ ┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ │ Block │ - │ training: False │ │ │ │ │ float32[128,64,120] │ x: │ │ │ │ │ - training: False │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_0 │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ MultiHeadAttention_… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ FeedForward_0 │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ FeedForward_0/Seque… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ FeedForward_0/Dense… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ FeedForward_0/Dense… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ FeedForward_0/Dropo… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ │ │ │ Total │ 188,880 (755.5 KB) │ └──────────────────────┴──────────────────────┴──────────────────────┴─────────────────────┴──────────────────────┘ Total Parameters: 188,880 (755.5 KB)
Full Model#
vocab_size = ts.vocab_size # Vocabulary size from the text processor instance
class BigramLanguageModel(nn.Module):
"""
A Bigram Language Model using a neural network approach with Flax's linen module.
This model uses embedding layers, a sequence of blocks, and a final dense layer
to predict the next token in the sequence.
"""
@nn.compact
def __call__(self, idx, training):
"""
Process the input indices through the model and compute logits for next token prediction.
Parameters:
idx (array): Input tensor of token indices.
training (bool): Flag indicating whether the model is training.
Returns:
array: Logits representing the probability distribution of the next token.
"""
logger.debug(f"Input shape in __call__: {idx.shape}")
B, T = idx.shape
tok_emb = nn.Embed(vocab_size, N_EMBD, name="TokenEmbedding")(idx) # Token embeddings
pos_emb = nn.Embed(BLOCK_SIZE, N_EMBD, name="Position Embedding")(jnp.arange(T)) # Positional embeddings
x = tok_emb + pos_emb # Combine embeddings
x = nn.Sequential([Block() for _ in range(N_LAYER)])(x, training=training)["x"]
x = nn.LayerNorm(N_EMBD, name="LayerNorm")(x)
logits = nn.Dense(vocab_size, name="Final Dense")(x)
return logits
def generate(self, max_new_tokens):
"""
Generate a sequence of tokens using the model.
Parameters:
max_new_tokens (int): Maximum number of new tokens to generate.
Returns:
array: Indices of the generated tokens.
"""
idx = jnp.zeros((1, BLOCK_SIZE), dtype=jnp.int32) * 4
key = jax.random.PRNGKey(0) # Key for randomness
for i in range(max_new_tokens):
logits = self.__call__(idx[:, -BLOCK_SIZE:], training=False)
logits_last_t = logits[0, -1]
key, subkey = jax.random.split(key)
idx_next = jax.random.categorical(subkey, logits_last_t)
idx = jnp.atleast_2d(jnp.append(idx, idx_next))
return idx
# Create an instance of BigramLanguageModel and configure logger
bglm = BigramLanguageModel()
logger.setLevel(logging.DEBUG)
# Prepare input tensor
input_x = jnp.ones((BATCH_SIZE, BLOCK_SIZE), dtype=jnp.int16)
logger.debug(f"Input tensor shape: {input_x.shape}")
DEBUG:notebook:Input tensor shape: (128, 64)
# Initialize the model
initial_params = bglm.init({'params':PARAMS_KEY, "dropout": DROPOUT_KEY}, input_x, training=True)
initial_params["params"].keys()
DEBUG:notebook:Input shape in __call__: (128, 64)
dict_keys(['TokenEmbedding', 'Position Embedding', 'Block_0', 'Block_1', 'Block_2', 'Block_3', 'Block_4', 'Block_5', 'LayerNorm', 'Final Dense'])
print(bglm.tabulate({'params': PARAMS_KEY, "dropout": DROPOUT_KEY}, input_x, training=False,
console_kwargs={'force_terminal': False, 'force_jupyter': True},
column_kwargs={'width': 400}))
DEBUG:notebook:Input shape in __call__: (128, 64)
BigramLanguageModel Summary ┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓ ┃ path ┃ module ┃ inputs ┃ outputs ┃ params ┃ ┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━┩ │ │ BigramLanguageModel │ - int16[128,64] │ float32[128,64,65] │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ TokenEmbedding │ Embed │ int16[128,64] │ float32[128,64,120] │ embedding: │ │ │ │ │ │ float32[65,120] │ │ │ │ │ │ │ │ │ │ │ │ 7,800 (31.2 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Position Embedding │ Embed │ int32[64] │ float32[64,120] │ embedding: │ │ │ │ │ │ float32[64,120] │ │ │ │ │ │ │ │ │ │ │ │ 7,680 (30.7 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Sequential_0 │ Sequential │ - │ training: False │ │ │ │ │ float32[128,64,120] │ x: │ │ │ │ │ - training: False │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0 │ Block │ - │ training: False │ │ │ │ │ float32[128,64,120] │ x: │ │ │ │ │ - training: False │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_0/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1 │ Block │ training: False │ training: False │ │ │ │ │ x: │ x: │ │ │ │ │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_1/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2 │ Block │ training: False │ training: False │ │ │ │ │ x: │ x: │ │ │ │ │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_2/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3 │ Block │ training: False │ training: False │ │ │ │ │ x: │ x: │ │ │ │ │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_3/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4 │ Block │ training: False │ training: False │ │ │ │ │ x: │ x: │ │ │ │ │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_4/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5 │ Block │ training: False │ training: False │ │ │ │ │ x: │ x: │ │ │ │ │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/LayerNorm_0 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ MultiHeadAttention │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ MultiHeadDotProduct… │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - mask: │ │ │ │ │ │ float32[128,1,64,64] │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ DenseGeneral │ float32[128,64,120] │ float32[128,64,6,2… │ bias: float32[6,20] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,6,20] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ DenseGeneral │ float32[128,64,6,20] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[6,20,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/MultiHeadAt… │ Dense │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,120] │ │ │ │ │ │ │ │ │ │ │ │ 14,520 (58.1 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/LayerNorm_1 │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/FeedForward… │ FeedForward │ - │ float32[128,64,120] │ │ │ │ │ float32[128,64,120] │ │ │ │ │ │ - training: False │ │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/FeedForward… │ Sequential │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/FeedForward… │ Dense │ float32[128,64,120] │ float32[128,64,480] │ bias: float32[480] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,480] │ │ │ │ │ │ │ │ │ │ │ │ 58,080 (232.3 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/FeedForward… │ Dense │ float32[128,64,480] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[480,120] │ │ │ │ │ │ │ │ │ │ │ │ 57,720 (230.9 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Block_5/FeedForward… │ Dropout │ float32[128,64,120] │ float32[128,64,120] │ │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ LayerNorm │ LayerNorm │ float32[128,64,120] │ float32[128,64,120] │ bias: float32[120] │ │ │ │ │ │ scale: float32[120] │ │ │ │ │ │ │ │ │ │ │ │ 240 (960 B) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ Final Dense │ Dense │ float32[128,64,120] │ float32[128,64,65] │ bias: float32[65] │ │ │ │ │ │ kernel: │ │ │ │ │ │ float32[120,65] │ │ │ │ │ │ │ │ │ │ │ │ 7,865 (31.5 KB) │ ├──────────────────────┼──────────────────────┼──────────────────────┼─────────────────────┼──────────────────────┤ │ │ │ │ Total │ 1,156,865 (4.6 MB) │ └──────────────────────┴──────────────────────┴──────────────────────┴─────────────────────┴──────────────────────┘ Total Parameters: 1,156,865 (4.6 MB)
Sample Generation#
This is with initial parameters that are totally random.
# Configure logger to not propagate messages to higher level loggers
logger.propagate = False
# Create an instance of BigramLanguageModel
bglm = BigramLanguageModel()
# Generate a sequence of tokens using the model and initial parameters
idx = bglm.apply(initial_params, 50, method='generate')
# Decode the generated indices back to text using the text processor's decode method
decoded_text = ts.decode(idx.tolist()[0])
# Optionally, print or process the decoded text further
print(decoded_text)
brCqDW!cVenexdcDOJhoE.:qwwC'ESzBDoXvJoCFcTO;R!DZ H
Training#
# Set the learning rate for the optimizer
LEARNING_RATE = 1e-2
class TrainState(train_state.TrainState):
"""
Extends the flax TrainState to include the dropout key in the training state.
"""
key: jax.Array
# Initialize the training state with the model's apply function, parameters, and an optimizer
state = TrainState.create(
apply_fn=bglm.apply,
params=initial_params,
key=DROPOUT_KEY,
tx=optax.adam(LEARNING_RATE)
)
@jax.jit
def train_step(state: TrainState, inputs, labels):
"""
Performs a single training step.
Parameters:
state (TrainState): Current state of the training including parameters.
inputs (array): Input data to the model.
labels (array): Target labels corresponding to the input data.
Returns:
tuple: Updated training state and the computed loss for the step.
"""
# Update the dropout key based on the current training step
dropout_train_key = jax.random.fold_in(key=state.key, data=state.step)
def cross_entropy_loss(params):
"""
Computes the cross entropy loss for a set of parameters.
Parameters:
params (dict): Model parameters.
Returns:
tuple: Loss value and logits from the model's forward pass.
"""
logits = bglm.apply(params, inputs, training=True, rngs={'dropout': dropout_train_key})
logger.debug(f"Logits shape: {logits.shape}")
loss = jnp.mean(optax.softmax_cross_entropy_with_integer_labels(logits=logits, labels=labels))
return loss, logits
grad_fn = jax.value_and_grad(cross_entropy_loss, has_aux=True)
(loss, logits), grads = grad_fn(state.params)
state = state.apply_gradients(grads=grads)
return state, loss
# Debugging output to inspect parameters and step count
print(state.params["params"].keys())
dict_keys(['TokenEmbedding', 'Position Embedding', 'Block_0', 'Block_1', 'Block_2', 'Block_3', 'Block_4', 'Block_5', 'LayerNorm', 'Final Dense'])
print(f"Training step count: {state.step}")
Training step count: 6
Training Loop#
This model was trained on my RTX 4090. It took about 30 minutes to train.
# Set the logger to debug level
logger.setLevel(logging.DEBUG)
# Training configuration
EVAL_INTERVAL = 100
CKPT_DIR = 'ckpts' # Set an absolute path for the checkpoint directory
EPOCHS = 10000
losses = [] # List to store loss values
# Split the random key for training and dropout
train_key, dropout_key = jax.random.split(ROOT_KEY, num=2)
# Main training loop
for epoch in tqdm(range(EPOCHS)):
# Generate a new random key for the current training step
train_key = jax.random.fold_in(key=ROOT_KEY, data=state.step)
# Fetch a new batch of data
xb, yb, ix = ts.get_batch(train_key)
# Perform a training step and capture the loss
state, loss = train_step(state, xb, yb)
losses.append(loss)
# Periodically evaluate and report the loss
if epoch % EVAL_INTERVAL == 0 or epoch == EPOCHS - 1:
print(f"Epoch {epoch}: Train Loss {loss:.4f}")
# Update model parameters
checkpoints.save_checkpoint(ckpt_dir=CKPT_DIR,
target=state,
keep_every_n_steps=100,
prefix='nn_compact',
overwrite=True,
step=epoch)
Epoch 0: Train Loss 2.9735
Epoch 100: Train Loss 2.5170
Epoch 200: Train Loss 2.3874
Epoch 300: Train Loss 2.2306
Epoch 400: Train Loss 2.0848
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[51], line 22
19 xb, yb, ix = ts.get_batch(train_key)
21 # Perform a training step and capture the loss
---> 22 state, loss = train_step(state, xb, yb)
23 losses.append(loss)
25 # Periodically evaluate and report the loss
File <string>:1, in <lambda>(_cls, count, mu, nu)
KeyboardInterrupt:
Training Loss#
fig, ax = plt.subplots()
ax.plot(np.arange(EPOCHS), losses)
ax.set_xlabel("Training Step")
ax.set_ylabel("Training Loss")
Text(0, 0.5, 'Training Loss')
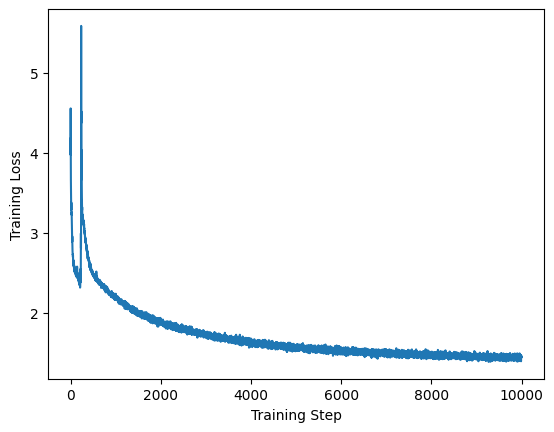
Final Results#
We can now use our weights to generate text. At a glance, it’s not bad.
# Configure the logger to information level
logger.setLevel(logging.INFO)
# Generate text using the current state parameters
idx = bglm.apply(state.params, 600, method='generate')
generation = ts.decode(idx.tolist()[0])
print(generation.strip()) # Print the generated text, stripped of leading/trailing whitespace
MENENIUS:
COMINIUS:
Why, sir, or hast been so what I did;
Respect is his, and go with holds,
And backs hangment tomb, Camillo true,
To speak no away in this son of roopiness;
Whithe that is all for you was, kind how I am
Hope for you as time our place.
LARTIUS:
Alas, only to love, to ho,
Him it with the cause to one this, bitter her
May a shepherd haze. Angelo.
But one till the officers to this true,
Thus expect us was unto the; for I am every begue;
And come unto our bild, man, then joy in his Pome.
BENVOLIO:
How down seems be my voiciant is upon himself,
And since him out of a diath. whom
Comparing Checkpoints#
What’s interesting is going back in time and comparing generations from different checkpoints. Since we saved earlier checkpoints, we can load them and see what the LLM had learned up to that point.
Checkpoint 501#
ckpt_301 = checkpoints.restore_checkpoint(ckpt_dir=f'{CKPT_DIR}/nn_compact301', target=None) # Restore model from a specific checkpoint
# Generate text using the restored model parameters
idx = bglm.apply(ckpt_301["params"], 600, method='generate')
generation = ts.decode(idx.tolist()[0])
print(generation.strip())
o sand Ah tiat,eNyh , t silenod has
d Aobe
Dh,hacr lolipr lh s teisihh mosaaOgn niyaUhrl T,! In
r Bsl a Ime Hot mor CLhtqIw tre Smellosh
t nleawe IiACtl Nssor NCtroh iteke;sacr Ie tg bi:slalrf,sarerygdaaYiku S noS konddiy:iM Hhusote
VA,iktrodh: toweisteuRsodl
AAuHtstopm r :rloRIshtla o,raboc N:w t to
-Ln tOate mo s
Hgr Sub.
TTk h xnehaoao,hehaiAme wheyouok n
ursowfed r .cw s Kboof r ms toA'tiGWtoRfawon
beeTm Mnaufowazirrse tab;gfyosor Ite
Wdochagu pe r se itIr t vol wy Cp omaatit leher
tiBSen,iPd ek tor Uubheoryan r
f ser m borcses Mdi-k diumubfciOElsamfeunrcisiLun gsh Von REaAITratle bh?e
Checkpoint 1101#
ckpt_1101 = checkpoints.restore_checkpoint(ckpt_dir=f'{CKPT_DIR}/nn_compact1101', target=None)
idx = bglm.apply(ckpt_1101["params"], 600, method='generate')
generation = ts.decode(idx.tolist()[0])
print(generation.strip())
Thostou phithat, Nous, theey, ou has deave sow, a'r couth now sthensing mustatgn nind
Irlls, wencir Beloa I you the gard me weere bolllon bothe awngeis
Wonksser! Cordowitike;
What to greimstant for frighe ming andoo kend staioud us bear tikirought
Heeinte; sodllleantst:
my to love nour h, abe it wit to band,
at omonst gravubstink hext have sheais we wheave, andsesth, I mu.
As sooof warstt yould tould thue ep.
Morclowaze-
Andt beavy sor I hat ochesuspe pese it dame Allll my omantinge.
TROFBUCHANP IESTHARD UV:
You me hand me ma, you, midisk dighur:
O that fout cist trecs: Von heave hat now spa
Checkpoint 5901#
ckpt_5901 = checkpoints.restore_checkpoint(ckpt_dir=f'{CKPT_DIR}/nn_compact5901', target=None)
idx = bglm.apply(ckpt_5901["params"], 600, method='generate')
generation = ts.decode(idx.tolist()[0])
print(generation.strip())
KING EDWARD IV:
You should be our us;n all some acculous;
Respemions his jotal no in shrl beawen to Bilianca
Angromer Captque true of soldiers, away is
Wondomen to roogion by mertaint, being the sakery
Backing and of thy son. Though say the poover
His stoublt loooks stop not: love he fir,
Him it with seen at a toloner gracuble,
That I have should be when woman.
BENVOLIO:
Why, sir, no must you pray! I thus explumply was:
The tabegot sorrow wedow again; and compract our
Company at their match exputine.
GLOUCESTER:
How farewell,
Is it is to dismublcients, for this man could
Thee a dranged by M