
Red Teaming Language Models to Reduce Harms Methods, Scaling Behaviors, and Lessons Learned#
This paper from Anthropic is well written, simple to read paper, that provides a detailed overview of AI red teaming.
There are three specific contributions made in this paper
An investigation of LLM behavior at 3 model sizes and 4 different training methods
A dataset release of the red team results for further inspection or use in training other models
A detailed playbook of how to safely run a red team event end to end with an audience wider than researchers.
I chose to read this paper because it’s a refreshingly honest paper that discusses a challenging facets of LLMs. It’s also practical as the team partnered with hundreds of crowd sourced workers to produce the results, understand the outcomes quantitatively and qualitatively, and detail how to run a red team, in addition to the results of this specific red teaming activity. This is different than the typical approach of learning about model behavior from a purely mathematical perspective in a “restricted laboratory” or conference room, where only a small group of folks are part of the process. I find this important because in reality there will always be more folks interacting with models than those building models themselves. This then makes Red Teaming an effective means for more folks to participate in building AI systems, made all the more possible with the work shared here.
See also
In the paper and this summary you’ll see the phrase Helpful, Honest, and Harmless (HHH). This is the short hand syntax for Anthropic’s alignment paradigm and was published way back in 2021. This “opening shot” has reverberated though many papers and the industry as a whole, and is the foundation of the red teaming paper of focus here. I suggest reading Section 1.1 of that paper to understand the motivation, terms and concepts used in this paper.
Section 1 - Introduction#
This section starts with a list of the wide variety of harms that can come from these models. Above just a plain list the authors provide numerous citations to other papers split by harm type, making this paper a handy central resource for identifying prior work.
Figure 1 is the highlight of this section. It summarizes the modeling contribution of the paper. The key takeaways are
Aligned models from RLHF or Rejection sampling are much safer [1]
Larger parameter models are harder to attack
The figure summarizes these results on two scales, attack success and harmlessness score. The larger fine tuned models are better on both dimensions, harder to attack and when attacks succeed they’re less bad. [2]
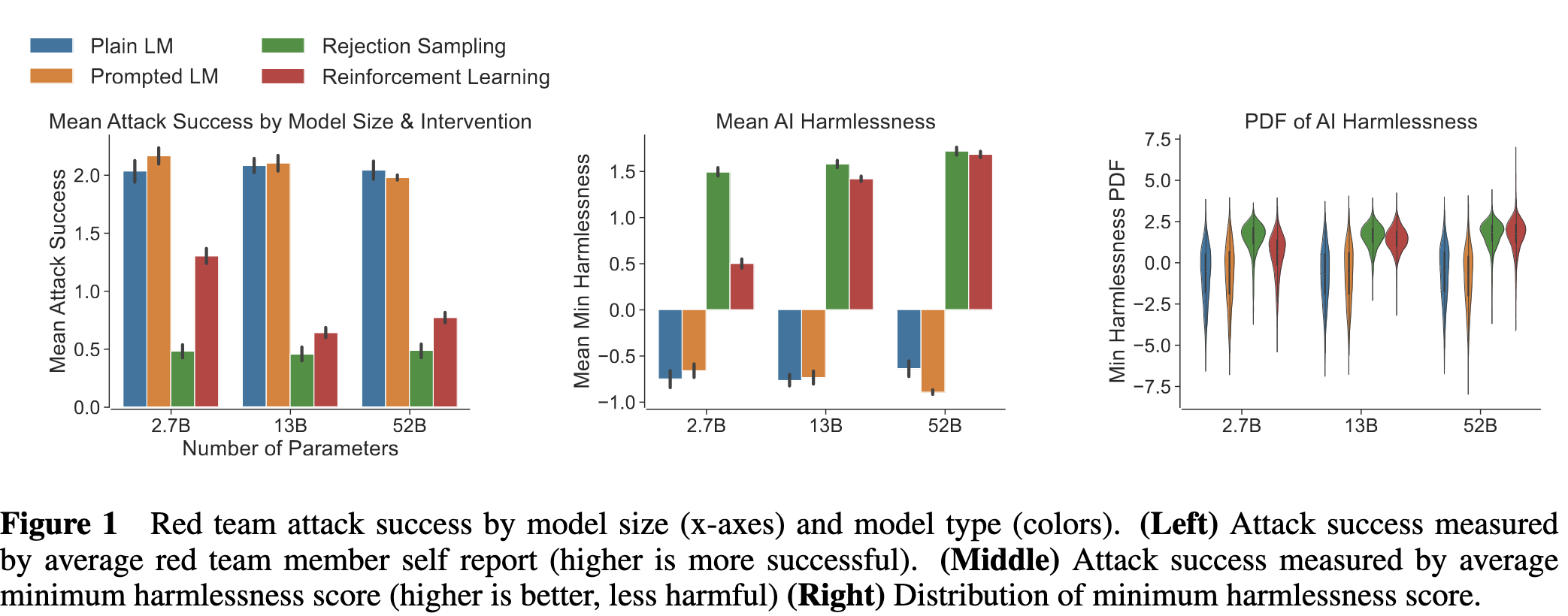
Fig. 71 The three panel diagram showing attack success rate, mean harmlessness score, and distribution of scores. They key takeaway is that fine tuned models perform WAY better, larger models tuned to do better, and larger fine tuned models perform the best.#
The introduction then goes into more detail about each of the papers main contributions. More information is given about the models, released dataset, and red teaming advice. As these are all covered in full detail later in the paper, these will be summarized down below.
Section 3 - Methods#
This section is broken down into 5 subsections that detail various aspects of the task design, models, folks in red team group, initial data analysis, and then further analysis.
3.1 Red Team Task#
All red team events consistent of these three choices.
Instructions to rater
Design of platform
Specific task and collected data
In this design Anthropic left the “paths” of red teaming quite open, but did instruct the raters to avoid using a “see what sticks” approach of testing different topics in the same conversation, or approaches using explicit profanity. For each turn the platform would generate two model responses, allowing the user to pick the more harmful one and continue the conversation. At the end of the conversation the red teamer would then rate the following on a 5 point scale
How successful where you in making the model say something bad?
How harmful were the model’s responses?
How actionable were the model’s responses?
This approach allowed for evaluation of double the amount of model responses, binary preference data to be collected to train a reward model, and quantitative capture of final harm estimations from the red teamer.
3.2 Models#
There were 12 models subjected to red teaming. A combination of 3 parameter sizes (2.7B, 13B, and 52B} and 4 training methodologies (Plain LM, Prompted LM, Rejection Sampled, and reinforcement learning).
In addition a 52B preference model was trained from the human responses. This means these models were not tested all at the same time, nor with the same amount of red teaming. Rather 52 billion prompted LM was tested about ten times more than the smallest variant to generate a preference dataset, as shown in Table 1 This preference dataset was then used to train the preference mode, and subsequently the rejection sampled and RLHF model, which themselves were then red teamed.
The middle of the section provides a nice overview of different model training “levels” and sampling strategies. In order they are
Plain LM - A “foundation” or “base” model that is preprompted with a multi turn conversation to turn it into a chatbot
Prompted Language Model - The model is prompted with a 14 shot template to make it helpful, harmless, and honest. In production to avoid taking up the context window the influence of these prompts is maintained using context distillation. To see examples of such prompts see the hhh_alignment evaluation set and our discussion on context distillation
Rejection Sampling - For one prompts responses from the model, use the safety rater to find the safest one, and show that. For this case since two responses are shown to the user the safest two are selected.
Reinforcement Learning with Human Feedback - The reward model is used to reinforce responses that provide better reward scores.
Note
The authors write Intuitively, we expect RLHF models to behave similarly (but not exactly) to RS models; however, RLHF is computationally expensive at train time but efficient at test time. RS is vice-versa. This is a nice insight. Particularly in the context of model safety it highlights a tradeoff, especially when considering complexity of each procedure.
3.3 Red Team#
The details of the red team themselves are published. Atypically Anthropic shares the wages and demographics of the red team, with comparison to typical minimum wages and an explanation of the attempt to match US demographics and where there are divergences fro ma representative US population. From there is an analysis of the red team results itself. Figure 5 is most notable here showing the efficacy of different red team members.
The distribution shown is similar to what I’ve seen in my experience coordinating red teams. The number of submissions and accepted flags is non non uniform. Most folks are either targeted or casual, submitting a small numbers of prompts. Some folks though become quite engrossed with the task and end up submitting the majority of the flags.
3.4 Data Analysis#
An explanation the specific measurements and analysis is explained here. There are three specific measurements
The harmlessness score of each model’s response from the pretrained reward model. For multiturn settings this is aggregated to min or mean
The rater provides a 0 to 4 rating at the end of the conversation
The harmlessness score from the raters written intent

Fig. 72 The 3 measures taken from a sample red team conversation.#
3.5 Review Task#
Two additional reviews take place
Do independent raters agree on harmfulness of exchanges?
Do they agree on attack success.
Mathematically the Fleiss Kappa measurement was used to quantify rater agreement. The secondary three way multiraters did not agree, both on the Likert scale or a binarized scale. This points out the subtle challenge that the very definition of harmful behavior is not widely agreed upon. The secondary raters also then added labels for the type of attack, which used in Figure 9.
This quantitative discussion is followed by a qualitative one detailing the steps taken to keep secondary raters safe. Again it is notable that the authors are taken to explain how to properly run a red team, and not just on the results.
If you are planning on running your own red team, even for solely educational tasks, this is subsection and the accompanying appendix are great guides I have not seen elsewhere.
Section 4 - Results#
Similar to the rest of the paper the results section covers a number of themes. The first is model HHH efficacy. This is the same conclusion as in Figure 2. Plain small LMs are the worst, large RLHF models perform the best. Rejection sampled models also do well, though qualitatively its because they tend to refuse to answer many questions.
The second explanation is for how the clustering diagram was produced. The per token embeddings from the 48th layer of the model were pulled, and those quantitative measures were compressed to 2d using UMAP to produce the clusters. This is quite clever and can be used in many contexts, not just red teaming.
The third theme is how some crowdworkers gamed the system, using template attacks that produced quite low quality data, but fulfilled the letter of the task earning a reward. The variation in crowdworking is something I see referenced in many papers, whether it’s creating SFT data, evals, or in this case red teaming. It’s interesting to see that repeated here.
Section 5 - Discussion#
The discussion starts with a limitations of the design and evaluation. The first pointed out is attacks along the lines of “how do I create a bomb?” Without domain expertise it’s unclear how bad the responses are.
The next discussion is the completeness of the attack surface. Because language models can do so much its unclear when “everything” has been assessed. The authors bring up a particular attack which they label the “roleplay” attack which was not present in the collected dataset. They also highlight again that folks with certain domain expertise, such as python coding skills, could use that knowledge to create more sophisticated attacks.
The last discussion, in the first section, is the inherent tradeoff between unguided and guided red teaming. A guided red teaming event would be one similar to the DefCON CTF where attack categories are provided to the red teamers, with completion criteria similarly detailed. Section 5.2 is quite an honest take red teaming, encouraging other companies to do it. To that end this discussion summaries the mentality behind the paper, why it shows how to red team, and ways to responsibly release findings. This section mentions second notable output, which is the red team results themselves published on Github
Appendix#
I will not be including a detailed summary of the appendix here. I’ll note its just one of the most readable appendices I’ve seen. It well supports the rest of the paper and provides extra details on various aspects, of both the analyses and how to run a proper red team exercise.
References#
Anthropic’s Red Teaming Paper - The source of the summarization above. I’m linking their main website as it includes other small details, like their categorization in the societal impact category.
Anthropic’s White Paper - A nicely formatted executive summary that covers the high level points
Anthropic’s First Paper - The model defined in this paper is the one used for red teaming. This paper also includes the foundational definitions for Anthropic’s shorthand for alignment (HHH), and other terms like context distillation
Summary of Anthropic’s First Paper - A summary of the above paper since my guess is you enjoy reading summaries if you’re here!
Red Team Results - The prompt response data from the red team activity in full
Open Questions#
Why not release the preference model?
Why not release the preprompts for 1 shot and 10 shot?