
Tuning in 5, 15, 50 Minutes#
This is the “at-home guide” to fine-tuning with hands-on examples.
The constraints are what a typical individual has in terms of time, money, compute, and tolerance for frustration.
For a more general overview, see the Fine-Tuning overview.
The task is to make an LLM that outputs food recipes in Shakespearean JSON. Three approaches will be shown:
5 Mins - API Tuning a cloud model, where the cloud vendor abstracts most of the details away from you.
15 Mins - Prompt tuning using Ollama and its clever model configuration files.
50 Mins - Local Fine-tuning a model’s weights using Hugging Face SFT Tuner.
This is not a “perfect path” guide.
Not everything is possible at home, and the process isn’t always smooth.
I’ll explain all the limitations and challenges I ran into.
Here’s the summary:
API Tuning |
Prompt Tuning |
Local Tuning |
|
|---|---|---|---|
Pros |
You get access to massive models, and it’s pretty easy to get started. |
Easy and intuitive. |
You can do whatever you want. |
Cons |
Limitations to the degree of tuning, and you’re still subject to TOS and safety filters. |
Not actually fine-tuning. |
You have to figure out how to do it and find the compute to do so. |
Important
This guide is in draft status.
Tuning for Home User#
Tuning is a key step in modern LLM development and one of the key skills to learn for LLM developers, as explained in the Fine-Tuning overview. In this guide, we’ll directly fine-tune models taking the perspective of a home user. Now I must warn you, this is a normcore guide to tuning, both in terms of content and writing style. The original goal was to create a GGUF export fine-tuned Gemma 7b for use in Ollama, but I was unable to do that for reasons I’ll explain below. When reading online, it can feel like fine-tuning should be easy. Most tuning guides show a smooth path with a perfect result. Or that access to cluster-level compute with full engineering teams is common. This is not always the case, so this is the tuning guide for the rest of us. This guide is for a person who has a day job and wants to know how they can tune LLMs for their personal usage, or for the person who’s looking to try tuning at a small scale to get a sense of how production-scale tuning works. The hope is this gives you a realistic expectation of fine-tuning as an individual, and to understand, let’s first start with the constraints.
Compute Constraints#
The first limitation will be how much compute is accessible. For “sandbox” cloud model tuning, the limitations are simple. It’s whatever the compute vendor allows you. For local tuning, this will depend on your hardware. I personally own a desktop with a single Nvidia RTX 4090. Typically, the most important number tends to be how much GPU VRAM; in my case, that’s 24GB. If you’re considering building your own GenAI setup, take a look at the references where there are some handy flowcharts and VRAM calculators. And do know fine-tuning takes more resources than just running a model.
Time Constraints#
The next constraint is time. Aside from compute time, fine-tuning has several time costs that sometimes get ignored. This could include:
Obtaining Supervised Fine-tuning examples.
Rating side-by-side examples if using RLHF.
Debugging driver issues, API failures, and model failures.
For a real example, the LLAMA 2 fine-tuning team obtained 1,418,091 human binary preference comparisons for just one part of their fine-tuning. Assuming each review took 1 second each (which most certainly took more), that’s still 393 hours of non-stop rating time.
We're going to assume you have the same constraints as me, which is a day job and only a couple of hours after work where you want to keep looking at a screen. Speaking of time, I had assumed I was going to be able to write this guide in two weeks, but due to a number of unforeseen issues, it ended up taking over a month. Whether fine-tuning at home or at your job, be sure to budget more time than you think you need.
Money Constraints#
Of course, all these problems can be solved with money. This could be to pay for cloud computing, buy a bigger computer, pay for human rater time, or for OpenAI to train a GPT for me for over a million dollars.

Fig. 76 For the price of a Bay Area house, you too can have your own fine-tuned GPT Model#
But I already spent $3500 on this desktop, and I don’t make any money from this guide or the fine-tuned models, so we’re going to do this with a massive budget of $0. The references include alternative situations, such as someone who is willing to spend $15k on a computer, or work at a business and how access to these resources change some of these decisions.
References#
Which GPU for LLMS - The best guide on which GPU to pick for your home setup that includes both technical considerations, like a focus on inference vs. training, and practical considerations, such as suggesting used GPUs to save on cost.
Memory needs calculator for local models - Provides a simple formula to roughly estimate the GPU needs to run a model locally.
Another Memory calculator - A similar calculator but implemented in a web app with additional descriptions and models.
Shakespeare Recipe Fine-tuning#
In this guide, we’ll have a model output recipes but in a Shakespearean style and JSON like this.
Prompt: What is a recipe for apple pie
{
"ingredients": {
"Apples": 4,
"Cinnamon": 2 tablespoons,
"Sugar": 1/2 cup,
"Butter": 1/4 cup,
"Apple Cider Vinegar": 1 tablespoon
},
"Instructions": {
"1. Prepare the Oven": "Preheat the oven to 350 degrees Fahrenheit (175 degrees Celsius).",
"2. Slice the Apples": "Quarter the apples and thinly slice them. Arrange the slices on a baking sheet.",
"3. Sprinkle Cinnamon and Sugar": "In a separate bowl, combine the cinnamon, sugar, and butter. Mix well. Sprinkle the cinnamon-sugar mixture over the apple slices.",
"4. Add Vinegar": "In a small bowl, combine the apple cider vinegar and a pinch of salt. Mix well. Drizzle the vinegar mixture over the apple slices.",
"5. Bake": "Bake the apple slices in the preheated oven for 10-12 minutes, or until golden brown. Serve warm."
}
}
I picked this example because it addresses the most common questions I get about how to adjust either the tone or the structure. It also conveniently serves as a fine-tuning example that lends itself to supervised fine-tuning, that is, one that takes a prompt and response pair for training, rather than one that uses preference ratings in a side-by-side comparison, like RLHF or DPO, as I mentioned above when discussing collecting preference data.
With Supervised Fine Tuning, constructing examples from scratch is more straightforward, but even easier is creating examples from distillation of a larger model, which is what we'll do here.
Distillation#
Distillation is a method where an existing AI model is used to create examples to train other AI models, and it isn’t necessarily limited specifically to generating SFT examples. For our case, where we do need SFT examples, writing examples by hand would take a couple of hours, and hiring contract workers to write examples would take both time and money. As a home user, distillation is a “hands-off”, easy method to generate examples, since we just load an already trained model into memory and generate examples. Typically, larger models are used to create examples for smaller models, hence the origin of the term distill. But there is no fixed requirement that the model being distilled is larger than the model being fine-tuned. Actually, getting distillation examples is as simple as prompting a candidate model for the behavior you’re looking to replicate.
Here’s what that looks like using LLAMA2 locally; you can refer to the full notebook which shows all the code.
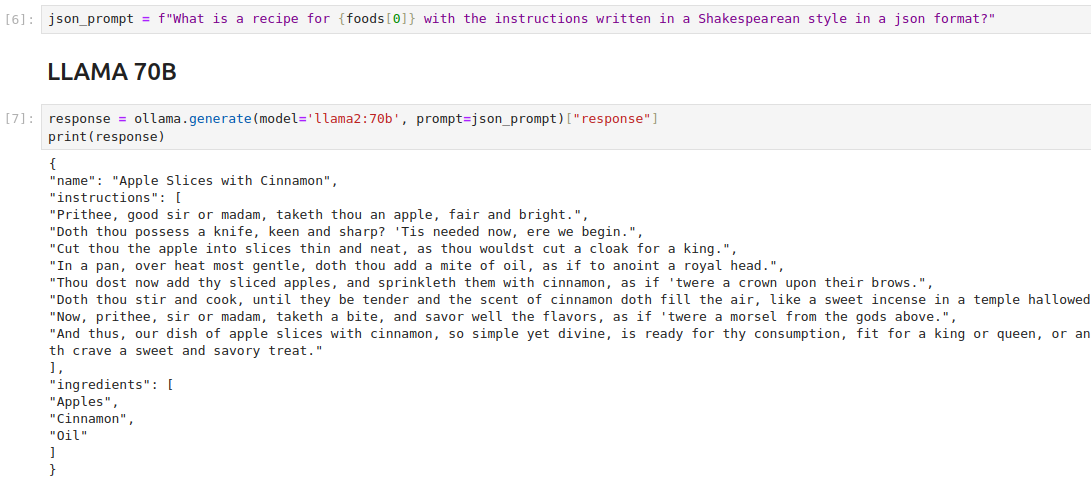
Fig. 77 Snippet of the distillation notebook used to produce the fine-tuning examples used here.#
The quality of these examples is very important, as with any machine learning problem the upper bound on the “goodness” of your model is determined by the quality of your training data. In addition to generating 20 examples from LLAMA 70B, I also do the same from Gemma 7B and Mistral 7B to get a sense of what different generations can look like and which one I like best. I picked these models in particular because I’m familiar with them, and I know they have good performance. I chose 20 examples because from experience I know this is enough for me to qualitatively evaluate each model’s output. I also know that 20 examples happen to be enough for as much fine-tuning as I want here. In your practice, you’ll need to determine what works for your use case, depending on your task, model, and level of fine-tuning.
One nuance to pay attention to is that we want our fine-tuned model to implicitly output a Shakespearean JSON, even if not requested. We also rewrite the supervised fine-tuning prompt. So stated specifically, for each supervised fine-tuning example, we are both obtaining a sample of the output AND rewriting the prompt.
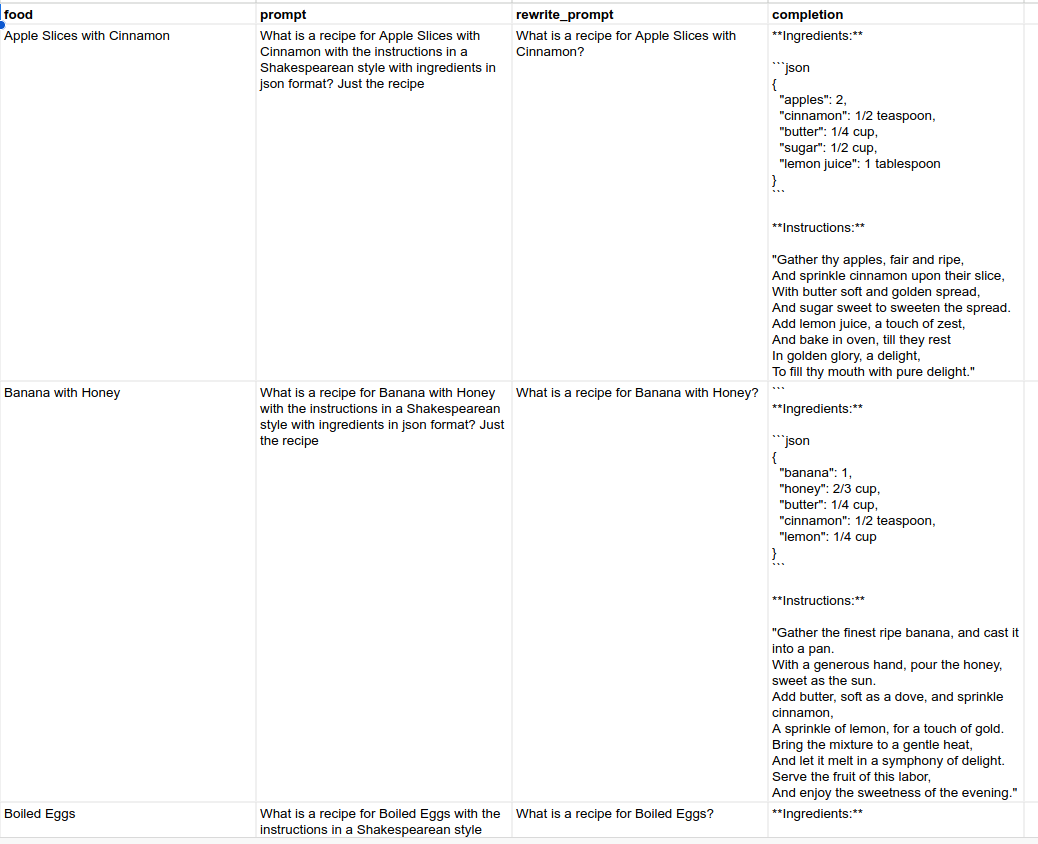
Fig. 78 Original, Rewritten, and Response examples.#
Now that we have our prompt example pairs, let’s get to fine-tuning.
Distillation only works if you have a trained model
To perform distillation, another model must already be good at that particular task. This means if you need to train either a new skill or a specific skill, distillation won’t be an option for you. Andrej Karpathy explains that here.
API Model Tuning#
I wager the most prevalent use of LLMs now is with models deployed on the cloud. Cloud models are:
Convenient to use
Always up to date
Often quite free or cheap to use
Most importantly, these models are the biggest and most capable models available and are certainly ones that you would not be able to run at home.
Within deployed models, there are typically two types:
Consumer products - Ones that you interact with through a front end, like ChatGPT
Developer APIs - Ones that developers interact with through APIs, like a Gemini API
Typically, it is not possible to fine-tune the chat interface models like ChatGPT. But typically, the API offerings usually include a tuning API, in addition to the generation API. These models are often packaged quite nicely for fine-tuning. The cloud vendors know their models well, and you’ll often get a lot of advice and guidance as part of the tuning product. You won’t need to fuss around with low-level details, as you’ll see later in this guide.
Gemini Model Tuning#
Let’s tune a Google Gemini model. For API models, I tend to use Gemini for two reasons:
I’m quite familiar with it given my day-to-day work.
More importantly, I can query and tune them for free in AI Studio, and so can you.
Tuning in AI Studio is largely a point-and-click affair. The steps are:
Build a dataset of inputs and outputs and put them in Google Sheets.
Follow the UI flow to specify in AI Studio.
The tuning process (Step 2) takes about 5 minutes. Here’s a video showing exactly how it’s done.
Here’s the difference between the original output and final response.
References#
OpenAI Tuning - OpenAI shows how to tune their model through their JSON API and which models they allow.
AI Studio Gemini Tuning - Similarly, Gemini and AI Studio show similar docs for tuning through a Python client, though AI Studio web app tuning is also available as shown above.
Local Model Tuning#
Small models, like Mistral and Gemma, are now available, which is a home user’s best gift. These are 2B to 7B parameter-sized models that fit on a CPU or consumer GPU quite readily. Since they’re local, you can run them wherever you want, even without the internet. And their smallness makes them simpler to tune, which is what we’ll do here.
TOS Still Applies
Like cloud models, there still are terms of service for these models. Reading them is a good idea, but not just to be an ethical person. They’re a good window into the thought process of foundation model builders, as they provide clues as to how the models work, and what experts in AI mention as notable.
Ollama Model “Tuning”#
Ollama is my go-to tool for local model management and inference. Ollama makes it simple to “pull”, manage, use, and lightly alter model behavior. It has all the interfaces I want, such as a command line chat, REST, and Python interfaces, making it easy to use LLMs in various settings. It also has a wide model library, often with multiple versions of the same model family. Best of all, it’s easy to try out new models through a Docker-like command-line management system. The Docker inspiration extends to its Modelfiles. This is an example Ollama Modelfile that overwrites the default system prompt.
FROM gemma:7b-instruct-q8_0
# sets a custom system message to specify the behavior of the chat assistant
SYSTEM You are a Shakespeare recipe bot, so be extra flowery in your language. Output all your recipes in JSON.
With this Modelfile defined, this model can be “built” and then run. Here’s a comparison of the difference in responses.
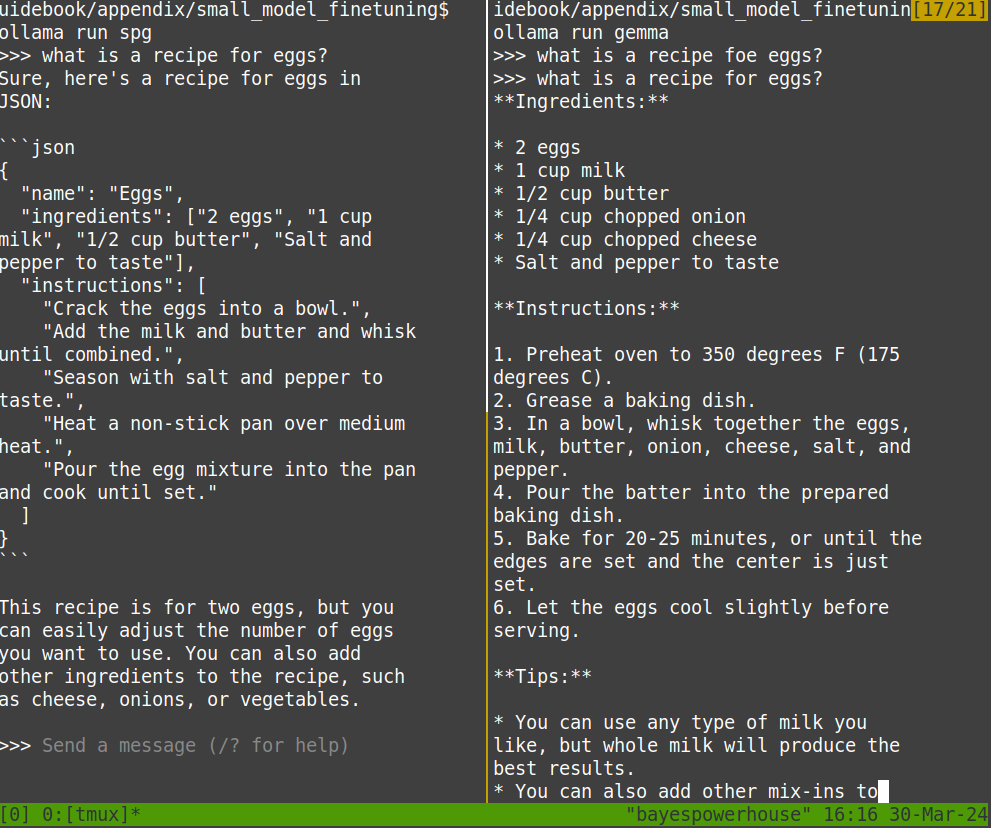
Fig. 79 A preprompted Gemma 7B on the left with “vanilla” Gemma 7B on the right.#
For a small preprompt, it’s not terrible. These Modelfiles contain various settings, including one that makes editing the preprompt quite straightforward. As a user, you can keep a library of Modelfiles that contain preprompts with instructions like “always respond in JSON” or “make summaries short”. For each task, the desired model+preprompt can be launched. This isn’t technically fine-tuning as the model weights are not changed, and we still have all the downsides of prompt tuning, which is extra inference cost and usage of the context window. Nonetheless, this is the most simple, straightforward way to get your own “GPT Agent” for most folks out there.
Local Supervised Fine-Tuning#
For local fine-tuning, Hugging Face provides a number of libraries and functionalities. As before, the ability to perform fine-tuning locally may be limited by your hardware, but also by your time and ability to handle frustration. You can see the end result in the Finetuning notebook.
In writing this, I spent numerous hours:
Reading through docs, blog posts, and help messages to figure out what cryptic error messages meant
Prompting every LLM out there for more help
Reinstalling CUDA, Python envs, and various libraries after numerous timeouts
Reading every GitHub issue about GGUF export
Even at the end of that, I learned that even with small models my compute is insufficient to export. But I did get a fine-tuned model, and you can learn from my challenges.
What worked: 4-bit PEFT Local Tuning#
With all machine learning problems, GenAI or otherwise, starting small is always the wise choice. For LLM local tuning, starting with a low bit quantized model, and a Parameter Efficient Tuning routine is the way to start small.
Quantization
Quantization is the process of reducing the model’s floating precision sizes to make it easier to fit models in memory. Typically, models are trained with high floating point precision so they learn with less noise, typically with something like 32-bit floats. The models are then quantized during serving to save on inference costs.
Unlike deployed Gemini tuning, there are many decisions and parameters that all have to be just right for everything to work. With HF tuning, I initially had to spend many hours understanding tensor formats, how SFT examples needed to be fed in, tokenizer issues, control sequences, and figuring out out-of-memory issues.
You can find the full notebook here. In the end, here’s what the original and fine-tuned versions looked like when compared.
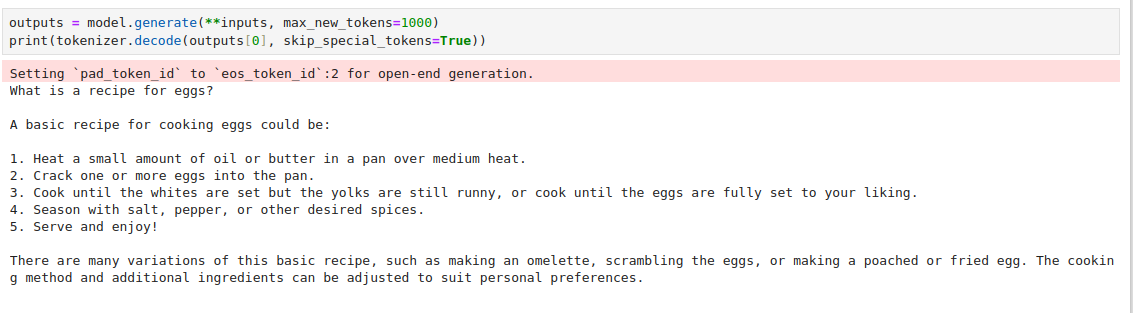
Fig. 80 The original generation from a Mistral 7B model from Hugging Face.#
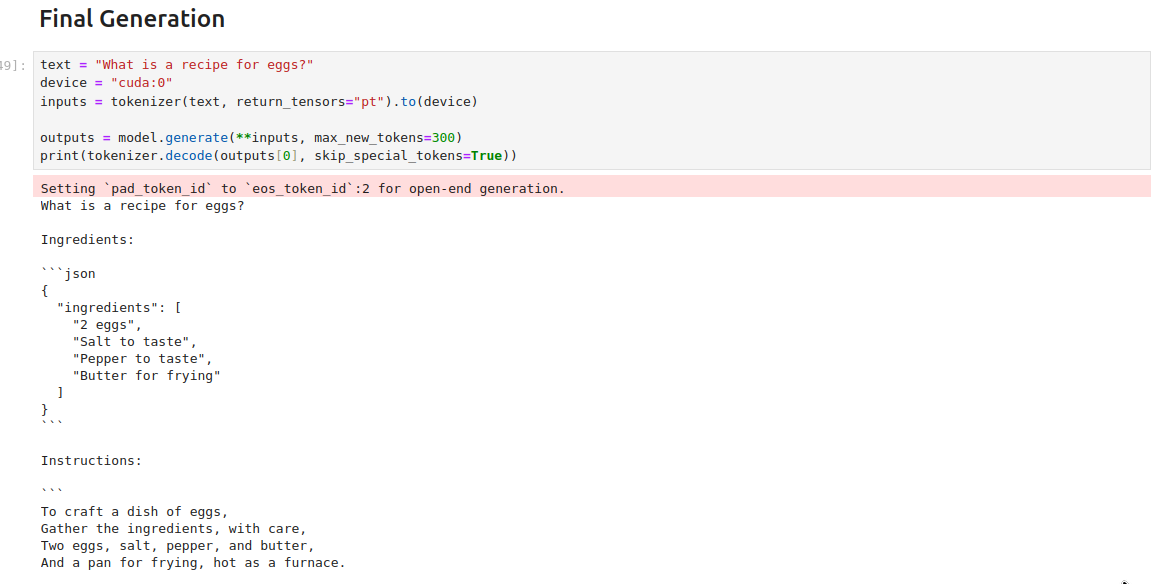
Fig. 81 The fine-tuned model.#
To do this, though, I ended up using nearly all my GPU capacity as measured by Nvidia’s monitoring tool, and this was with a quantized model and parameter-efficient tuning.
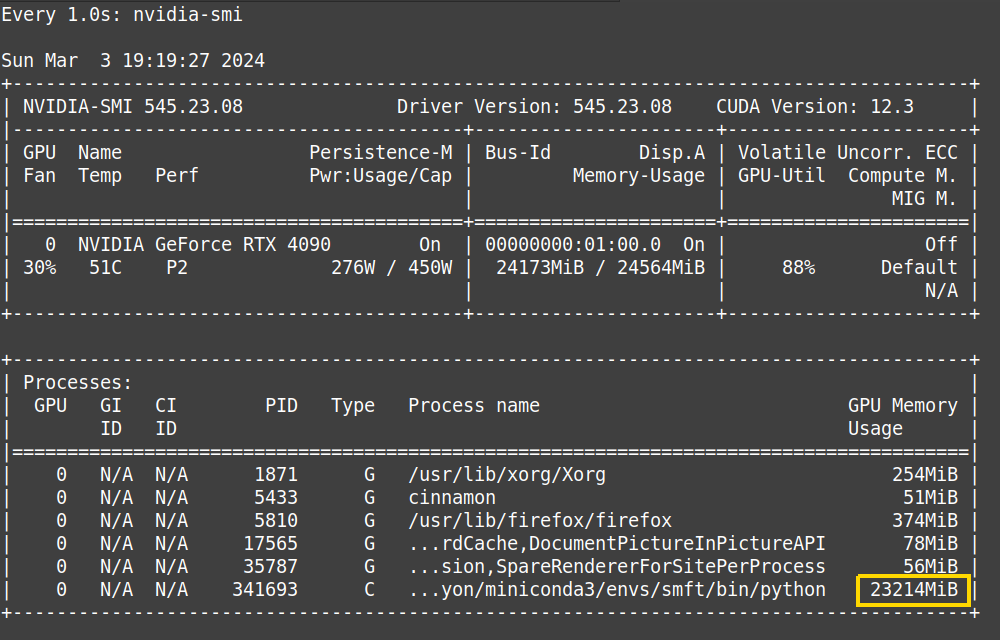
Fig. 82 The fine-tuned model.#
What didn’t work: GGUF Export#
While getting a Hugging Face inference model working was a nice step, to run the fine-tuned model, I would always have to load it in an HF library and query it from Python. This would make it harder for me to use locally, hard to distribute for others as well. Both restrictive and inconvenient. To run models in Ollama, the current norm is to convert them to GGUF format. This is a specialized LLM inference format that arose from the need for a better way to distribute models for usage in inference. The challenge is to do this you need two things:
An export script
Enough RAM to save your model in FP16
I was lacking the second for a Mistral 7B model, and both for a Gemma model. I learned this after spending hours finding out that exporting a Gemma model to GGUF would require some updates to a fairly large and convoluted Python export script. After switching to fine-tuning Mistral 7B, I learned that the script requires FP16 weights, and 24 gigabytes of memory in an RTX 4090 is insufficient to fine-tune at that precision. I’m not about to spend $10k on an A100, so this is the end of the road for me as a home tuner. But here are the next steps one could potentially take from here:
Rent Compute - Many cloud vendors are renting their compute out for folks to fine-tune. This includes the established “Big Three”, as well as many smaller startups whose entire cloud portfolio is focused on AI.
Buy two GPUs - This gets you more RAM. But it’s also going to get you more headaches in terms of dealing with physical, driver, and software configuration.
Get a TinyBox - TinyBox is an interesting product from hacker extraordinaire George Hotz, who is betting this hardware product, in conjunction with TinyGrad, can take a decent chunk out of the NVIDIA/CUDA ecosystem that is currently dominating AI training.
References#
https://gathnex.medium.com/mistral-7b-fine-tuning-a-step-by-step-guide-52122cdbeca8
https://huggingface.co/mistralai/Mistral-7B-v0.1/discussions/6o3
https://vickiboykis.com/2024/02/28/gguf-the-long-way-around/
Finetuning degrades performance https://youtu.be/c3b-JASoPi0?t=518
https://huggingface.co/Laurent1/Mistral-7B-Instruct-v0.1-QLoRa-medical-QA