
Large Language Models and Transformers Overview#
TLDR
Transformers are now widely used because they
scale extremely well
perform well across a range of tasks
Transformers were introduced in the paper Attention is all you need
The general is not different from small language models
The challenge a model that can flexibly learn language patterns in an efficient way
The key ideas are
attention can be further subcomposed into the queries, keys, and values
using softmax for layer activation
decoder and encoder stacks
Transformers#
Transformers are getting the most attention because they’re the NN architecture which can be reasonably be trained and produces the a great output. Transformers are able to capture patterns in the data in practice that previous architectures could not. Previous model structures markov chain approach weren’t flexible enough to learn the nuances of the same way neural net can. Previous Neural Network architectures had scaling or gradient problems where during training parameter estimation was taking too long or just failed. Transformers are structured in a manner that allows them to be trained readily and stably. And importantly they are just really good in many applications.
The main ideas Transformer#
This is the original picture of a transformer from the paper Attention is all you need. It seems complicated but really a few core intuitive ideas make the whole thing work which is quite amazing. Transformers and this paper, covered extensively so won’t go into detail, we’ll just cover the highlights and provide references to the best materials.
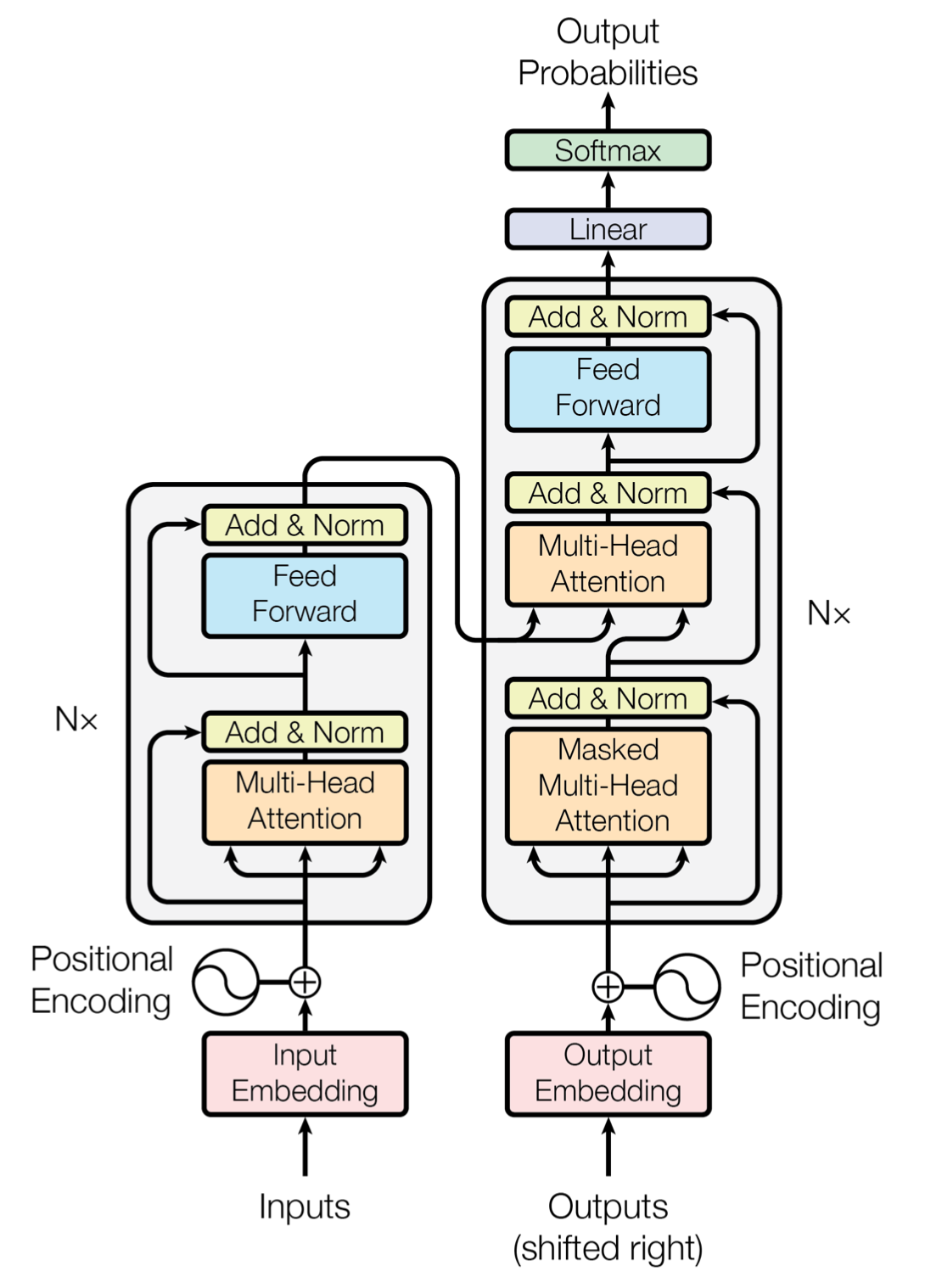
Fig. 3 The famous image from the Attention Is All You Need paper#
The parts we’re going to highlight are
Attention, comprised of a Query Key and Value
Decoder and Encoder
Softmax transform
Attention, Self Attention, and Positional Encoding#
This is the biggest idea as evidenced by the Attention is all you needVSP+23 paper name itself. The name attention indicates the core idea, In essence the model figures out what parts of its input it should “care about” and “what it shouldn’t. Think of the following question.
I went to the grocery store and hardware store, walked around and bought nails and bread. Which did I buy where?
As a human what do you pay attention to and, and what do you ignore? I’m sure you can explain it generally, but most of us, if asked to write a generalizable mathematical rule, would struggle.
The paper authors did write one such rule, called attention, and as of now nearly everyone is using it.
The core parts of attention are a
Query
Key
Value
Here’s an analogy from Lih Verma
You login to medium and search for some topic of interest — This is Query
Medium has a database of article Title and hash key of article itself — key and Value
Define some similarity between your query and titles in database — ex Dot product of Query and Key
Extract the hash key with maximum match
Return article(Value) corresponding to has key obtained
The explanation in blog post where a transformer is handmade also provides a great intuition, especially because the QKV matrix weights are set by hand leaving no ambiguity whatsoever in the calculation.
Softmax#
Softmax basically takes a vector of arbitrary length and turns it into a proper probability vector. In math it can look a little scary.
But in practice its quite simple. Here’s softmax implemented when implemented in libraries with broadcasting. Here’s the one liner.
x = [.3, 1.2, .8]
np.exp(x)/sum(np.exp(x))
And here’s the output.
array([0.19575891, 0.48148922, 0.32275187])
Now x has been transformed to a proper probability. In transformers softmax is prominently used at the end. However it’s also used within each self attention head as a normalizer and activation function which you can see in Flax here.
Relu activation vs Softmax
I’ve only skimmed this paper but it seems to offer a intuition on why softmax is a good activation function. https://arxiv.org/pdf/2302.06461.pdf
Decoder and Encoder Stacks#
When in the weeds of transformers architecture you’ll hear about encoder models, decoder models, and encoder decoder models. I have a loose grasp on this right now. This website explains it well but there are some nuances between decoder only, and encoder/decoder models that I don’t fully understand.
References#
3D LLM Visualization and Guide - A fantastic 3D visualization of LLMs with a very nice explanations.
Attention Implementation in Flax - This is a concise and fantastic code implementation. In particular is this line which decompose the query and key dot product, and this line which details the (query, key) and value dot product. The einsum notation in particular makes it quite clear what is happening.
Intuitive Explanation of Query Key and Value - A nice blog post that summmarizes this well
Attention is All You Need paper - The original paper for the transformer architecture that’s kicked off this whole craze.
Fantastic blog post on Transformers - Very well illustrated and easy to read
Softmax and temperature - A good explanation of softmax and also temperature, a concept we’ll come back to later.
Encoder vs decoder explained well - A good summary of how the different architectures are used with references to actual models
GPT in 60 lines of Numpy - A compact representation Numpy implementation of transformers and the full training stack.
End to End Guide to transformers - A fantastic guide that starts from basics of matrix multiplication, through Markov chains, to the fully built model.
Building a Transformer by hand, including the weights - This guide really cuts to the core of what transformer is, and with manual weight selection you really get an understanding of what’s hapenning.