
Key Ideas in RL#
TLDR
Reinforcement Learning (RL) is a set of “old” ideas now implemented on “new” LLMs
Effective Reinforcement Learning is really just understanding the core ideas and making smart choices for your situation.
The central concept of reinforcement learning:
is quite simple.
is applicable to many domains.
The complexity comes from:
the wide variety of options.
specialized terminology.
computational complexity.
RL is now widely used in LLMs to shape models models, particularly in areas that are verifiable
Verifiable rewards, 1+1=2 and 2+2!=5, and thinking modes have heavily changed LLM behavior and capabilities
By focusing on LLMs RL specifically, we can focus on common implementations to simplify learning and implementation.
RL Overview#
The foundational ideas of Reinforcement Learning have been developing for at least 40 years, finding applications in diverse fields like robotics or drug discovery. Over that time there are many sub fields and algorithms in RL that are optimized for each one of the challenges. In the last 4 years, interest in Reinforcement Learning has increased substantially with the rise of Large Language Models (LLMs). Models like ChatGPT brought Reinforcement Learning from Human Feedback (RLHF) to widespread attention, while earlier models like GPT-3 also used RL to achieve frontier levels of performance. These days, RL is a key tool when shaping LLMs, particularly in the later stages referred to as post-training. Now, because what works for winning at the game of Go won’t necessarily work for solving cancer, many different approaches to reinforcement learning have been developed. However the fundamental concepts are similar.
A Straightforward Idea with Many Nuances#
When reading through Reinforcement Learning literature, it can be easy to miss the forest for the trees. With many specific terms and mathematical formulae, it can be easy to get lost. This guide will cover the high-level ideas and basic terminology before we move on. Use it as a reference as you move through the subsequent notebooks.
The RL Loop#
The concept of reinforcement learning is quite simple, with direct parallels to everyday life. An agent takes actions, and it receives rewards. Some rewards are immediate; others take time to result in the final outcome.
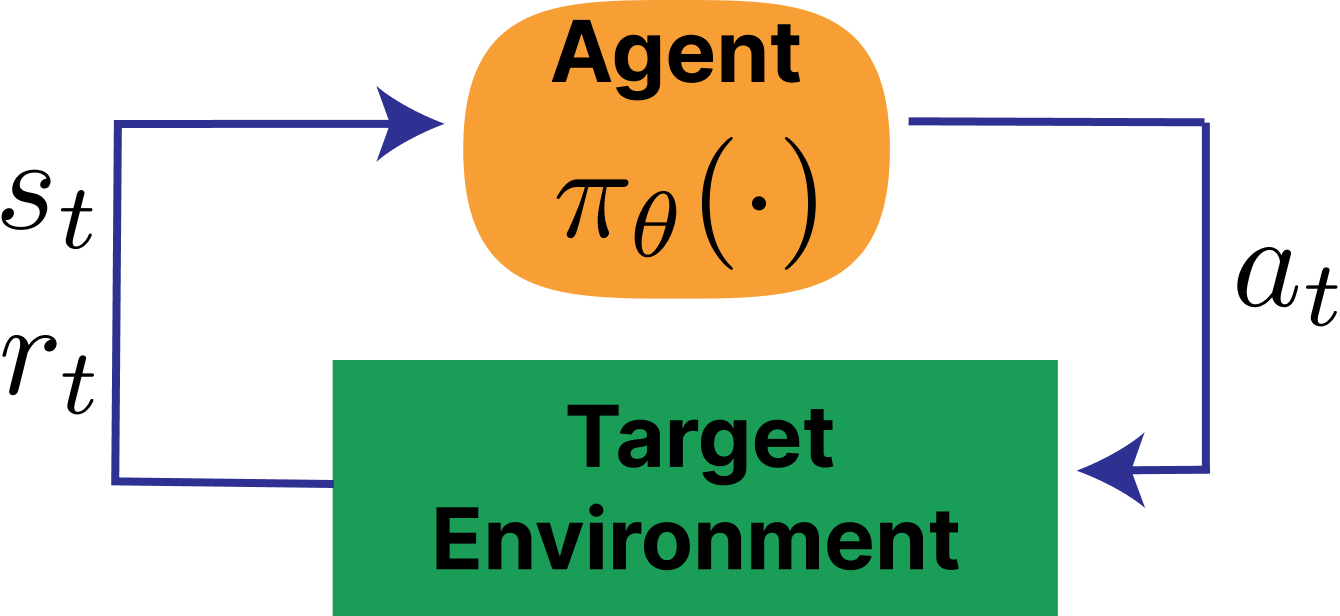
Fig. 25 Basic RL Loop from SpinningUp#
In this diagram, here are the definitions from Sutton and Barto:
\(a_t\) is the action the reinforcement learning agent takes in some environment, such as moving a chess piece.
\(s_t\) is the change in state, say the board state for chess.
\(r_t\) is the reward, say a reward for capturing a chess piece.
\(Agent\) is the action taker, and \(\pi_{\theta}\) is the policy: the algorithm that the Agent uses to take the next action.
\(Target\ environment\) - The thing it (the agent) interacts with, comprising everything outside the agent, is called the environment.
These five simple concepts are at the core of billions of dollars of funding and compute resources. They’re at the core of self-driving cars, recommendation systems in deployed web apps, Nobel Prize-level breakthroughs such as AlphaFold, and many other real-world systems.
Of course, this means there is a lot of reinforcement-specific jargon that comes with this domain, so let’s get into it!
The Terms and Key Concepts#
We’ll cover the most common terms that will be part of this guide. Described in just words, these terms can be confusing. If later on you are confused by these terms, come back to this page to reference the simple implementation before going back.
Environment(s)#
In addition to the textbook definition of “environment,” I personally make these two distinctions:
Deployed or Fixed Environment - The environment, e.g. users using LLMs on their own prompt or real-world conditions.
Constructed or Simulated Environment - An “artificially” constructed environment, such as a video game for self-driving cars.
State Terminology#
State - The status of an environment and the agent at a particular time step, e.g. speed, velocity, and adjacent car positions in a driving simulator, or piece position in chess.
Observation - What the agent perceives from the environment at a given time step.
Time Step - The series of steps that represent start to finish.
Episode - One “start to finish” iteration through the RL loop.
Trajectory - A sequence of states, actions and rewards from an episode.
Reward Terminology#
Rewards - The “goodness signal” received after taking an action. This could be positive or negative. Sometimes the reward is fixed, but often it can be designed by the RL researcher/implementor as well, especially with LLMs.
Return - The discounted reward at a certain step from a full trajectory.
Action Terminology and Policy#
Algorithm - The methodology in which an agent works during both learning and runtime. This is the most critical choice, as it has many downstream implications. See the diagram above.
Policy - The “algorithm” which picks the next action in a state. A policy maps a state to a distribution of probabilities over the action space.
Behavior Policy - The policy used to pick actions. For instance, we’ll be using epsilon-greedy policies in our Ice Maze example during training.
Target Policy - The policy being learned. For example, in Ice Maze, this is the greedy policy.
On Policy - On policy means the policy being used for exploration (the behavior policy) is same as the policy being learned (the target policy).
Off Policy - Off policy means the policy being used for exploration (the behavior policy) is different from the policy being learned (the target policy). In the next notebook you’ll see this case, the behavior policy is epsilon-greedy, while the target policy is purely greedy (always picking the best action in a state).
Challenges with RL#
However, while conceptually simple, reinforcement learning comes with a host of challenges:
Name |
Concept |
Challenge |
|---|---|---|
Explore vs. Exploit |
Deciding whether to stick with known successful actions or try new ones to find better rewards. |
Over-exploring wastes computation; over-exploiting leads to rigid models that fail in new situations. |
Bias-Variance Tradeoff |
Balancing the stability of policy updates against the flexibility to adapt to new data. |
High bias provides stability but lacks flexibility; high variance makes updates erratic and sensitive to noise. |
Environment Specification |
Defining the rules, states, and boundaries of the world the agent operates in. |
Simple for games like chess; extremely complex for real-world applications like autonomous driving. |
Sample Efficiency |
Maximizing the amount of learning achieved from every interaction with the environment. |
RL often requires millions of trials; learning effectively from a limited number of “loops” is costly and slow. |
Non-Stationarity |
Managing environments where the rules, dynamics, or goals change over time. |
An agent may become obsolete if the environment shifts (e.g., user preference drift or changing market conditions). |
Curse of Dimensionality |
Dealing with the exponential growth of possibilities as more state/action variables are added. |
It becomes mathematically infeasible to explore or map every possible combination as complexity increases. |
Observability |
The degree to which the agent can see the entire state of the environment at any given time. |
In “Partial Observability,” the agent must make decisions based on incomplete or noisy information. |
Reward Function Design |
Translating complex human goals into a mathematical scalar reward. |
Reward Hacking: The agent may find unintended shortcuts to maximize rewards without actually solving the task e.g. editing the timer rather than making a task faster. |
Credit Assignment |
Determining which specific action in a long sequence was responsible for the final outcome. Includes balancing between process(intermediate step) rewards, and outcome (completed output) rewards |
It is difficult to distinguish “good” actions from “bad” ones when the reward is delayed (e.g., a move in the beginning of a game). |
Sim-to-Real Transfer |
Training an agent in a simulation and then deploying it in the physical world. |
The Reality Gap: Minor differences in physics or sensors between sim and reality can cause the agent to fail. |
Catastrophic Forgetting |
The tendency of a model to lose previous knowledge when exposed to new information. |
Learning a new task can cause the agent to completely “forget” how to perform a previously mastered task. |
Generalization |
The ability of the agent to perform well in environments it did not see during training. |
Agents often “overfit” to specific training scenarios, making them fragile when small environmental details change. |
Safety & Constraints |
Ensuring the agent avoids dangerous or prohibited actions during the learning process. |
In robotics or healthcare, “exploratory” mistakes can lead to physical damage, injury, or ethical breaches. |
LLM Focus#
In this guide, we are focusing solely on LLMs, which means we focus on the algorithms on the far left of the diagram below. This includes algorithms such as PPO, and some not present on the diagram, such as GRPO.
Why focus on LLMs? Well, at least for two reasons:
To focus our foundational learning on a smaller set of concepts, for example actions taken in a discrete space.
Highlighting challenges specific to modern LLM deployments, such as the ambiguous nature of correctness in natural language.

Fig. 26 Various RL Algorithms#
Before getting to LLMs though, we’ll focus on a classic problem in RL to solidify the core concepts. Let’s get started in the next section!
Suggested Prompts#
Can you elaborate on the challenges of RL with LLMs?
Which RL Algorithms are not so suited for LLMs? Why is this the case?
References#
Spinning Up from OpenAI - A guide written by OpenAI researchers about RL before their era of LLMs.
Unsloth Guide to RL - The Unsloth folks build the most technically deep and practical content on the topics of model training, including RL. All their guides contain everything you need to DIY with fast implementations across a family of models.
OLMO Open Instruct/TULU Codebase - The full recipe from the AI2 team showing the details of what it takes to RL a frontier level LLM.