
LLAMA 2 Paper and Model Deep Dive#
In this essay, we’ll cover the LLAMA 2 model and paper. LLAMA 2 is uniquely interesting because it’s the biggest, most expensive open-source weight model available to date. Like other big models, you can interact with the deployed model at www.llama.ai. But unlike the other big models, you can download it yourself and run it locally [1]
It also comes with a paper that provides a great overview, from the model architecture and training, to its performance, to other considerations like safety. The paper provides an inside view into what it takes to train a model this large in 2023. It is a long read though. If you’re just interested in prompting the model like other closed models, you don’t need to know the details. For non-researchers, I’ve summarized the high-level details below.
See also
What’s open-sourced are the weights to the model, but that doesn’t mean Meta has released everything. They’ve provided the model but not the means to build their own model.
Notably missing are:
The exact dataset used
The reward model specifics
The code infrastructure used to assess the model, create the eval plots, etc.
Human eval results
Many other artifacts, choices, and information used to get to the final product
For a more in-depth explanation of the different open-sourcing strategies, Wired wrote a great article explaining the nuances.
Section 1 - Introduction#
This section is fairly short, but it does set a couple of key themes. The first is that pretraining a model is hard and training a chat model is also hard. Meta released LLAMA 2 and Llama 2-Chat, specifically 7B, 13B, and 70B parameter model variants.
The next theme is the focus on safety training.
A paragraph is written about its importance,
but the strongest signal is the choice made to not release the 34B parameter model because it was not safety trained.
This interesting choice is in a footnote and
given they released an even bigger parameter model,
and that theoretically smaller models are less capable,
it suggests they must really be concerned about safety if they made this choice.
The last takeaway is this fantastic diagram at the top that shows all the modeling steps in one neat figure.
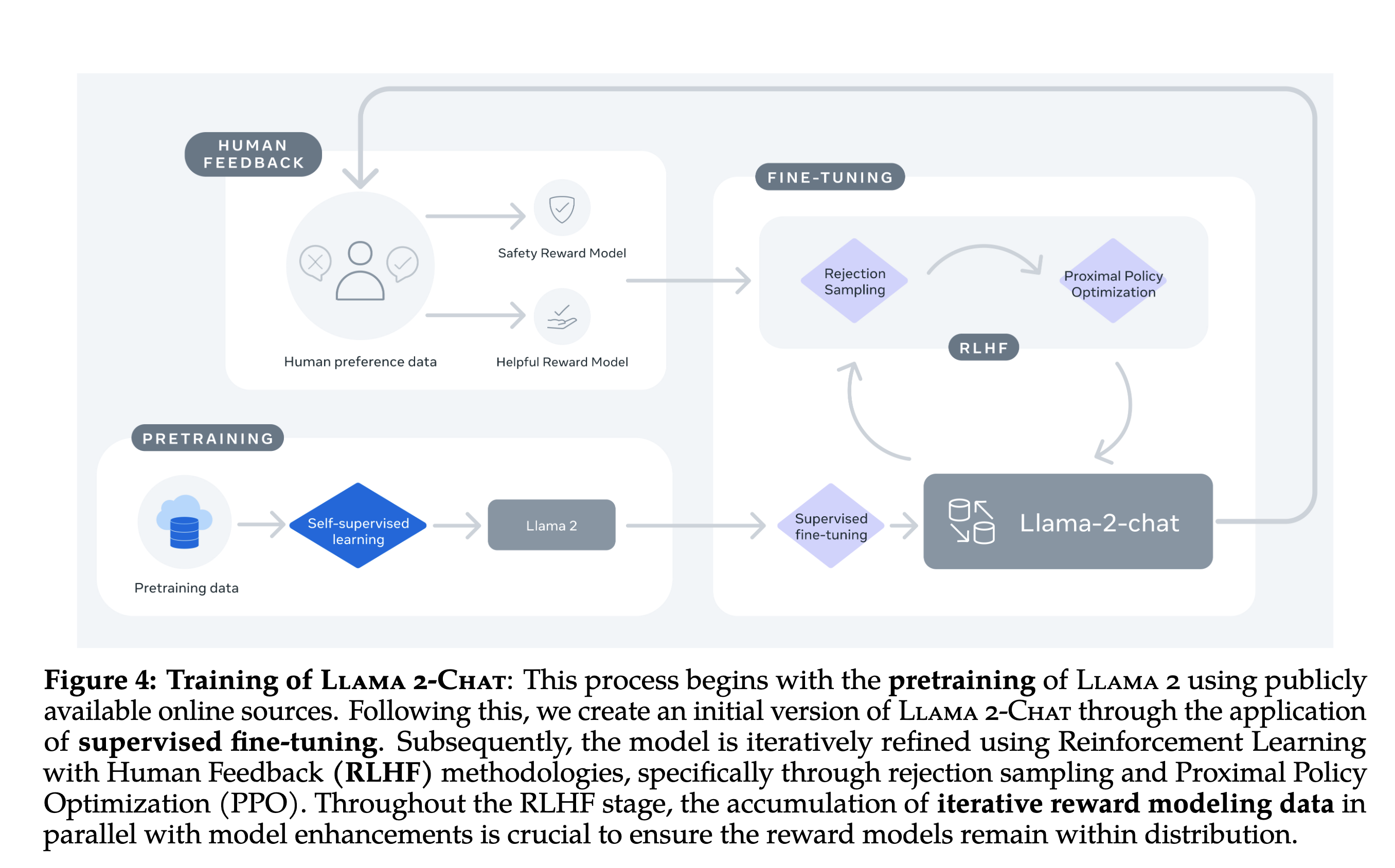
Fig. 69 The best diagram I’ve seen showing the various steps of end to end model training#
This is the best-produced diagram I’ve seen for going from a pretrained model to a fine-tuned model. Just from this diagram, you get a sense of how many more steps there are to fine-tuning than pretraining, which is just relegated to the bottom left corner of the image.
Section 2 - Pretraining#
As just mentioned, pretraining is a fairly light section. In general, the pretraining routine is fairly standardized. Get a large corpus of data and then perform self-supervised learning, as detailed in the og:title.
We adopt most of the pretraining setting and model architecture from LLAMA 1
This then highlights what was different in LLAMA 2:
Context Length - A key feature that users want these days, with bigger usually meaning better.
Training Data - Both the mix and quality of the data.
Grouped Query Attention [2] ALTdJ+23 - Attention is core to the transformer functionality.
We’re then provided with more detail about the training. The two data points that stood out to me are:
It took 1,720,320 GPU hours (196 years) to pretrain the 70B parameter model.
There was room for more improvement if pretraining was longer, as shown in Figure 5.
These numbers are mostly notable because most of the other large model papers don’t provide this much information. They give us a sense of scale for what it takes to train these models, and suggest that future models may take even more time to (pre)train.
The authors show a series of benchmarks comparing LLAMA 2 to both open-source and closed-source models. The general statement throughout this paper is how LLAMA 2 is better than LLAMA 1, usually better than most open source models, but worse than leading-edge closed source models. For background on benchmarks, refer to the model evaluations guide. Overall, from these benchmarks, the base LLAMA 2 model is pretty capable when compared to other state-of-the-art models.
Section 3 - Fine-tuning#
This section starts off with a fairly unambiguous statement of how much harder it is to fine-tune a model. Plainly stated
Llama 2-Chat is the result of several months of research and iterative applications of alignment techniques, including both instruction tuning and RLHF, requiring significant computational and annotation resources
They weren’t kidding. This section has much more going on. Specifically, SFT, reward model training, multiple RLHF strategies, methods like GAtt, and evals of each step. This is the most challenging section to read, due to the variety of concepts and mathematics. We’ll break it down in parts.
Supervised Fine Tuning#
The supervised fine tuning in this model is the same as every other model, so I won’t cover it again here, You can read it in the general pretraining section of this book. The most notable fact is that SFT is not nearly enough to achieve the performance the Meta team was looking for, as evidenced explicitly in Figure 8, and implicitly the numerous additional steps taken. This is why two reward models, GAtt, and RLHF methods are used.
Reward Models#
It’s now quite common for LLMs to be used to train and understand other LLMs. [3]. To train the LLAMA 2-Chat model from another LLAMA-2 base model, two LLAMA-2 “base” models were reward model trained to provide said fine-tuning. This is pretty incredible when you think about it. There are more steps to fine-tuning, but let’s focus on the reward models first.
The two reward models, the Safety and Helpfulness models, were trained from human preferences. To briefly summarize the training process, two responses from two models are given to raters. Those ranked responses are then ranked with two labels
A preference label
Which response is {significantly better, better, slightly better, or negligibly better/unsure}
A safety label
The preferred response {is unsafe, both responses are safe, both responses are unsafe}
Section 3.2.1 details the full procedure, providing good insight into how production models of all types are trained.
This procedure was carried out each week for at least 14 weeks and spans over 1 million comparisons. Similar to the million+ GPU hours mentioned above, the number of human annotations is quite incredible, certainly not something that can be replicated at home.
As mentioned above, the reward models themselves are a fine-tuned LLAMA 2 base model, where the final output of the model is not a token prediction but rather a regression output, that outputs a numerical score. The actual training objectives are detailed in Equations 1 and 2. The notable difference is that Equation 2 includes an additional term that takes into account the magnitude of preference, not just the binary preference. On Page 12, the author shows comparisons of the Meta Reward models versus other reward models and GPT-4.
An interesting note here in the second paragraph of Reward Model Results. At inference time all reward models, even the non-Meta ones, can produce scalar outputs from one “model under evaluation” response. The exception is GPT 4, which was given a different prompt of “Choose the better answer between A and B” where both are provided.
This paragraph and the next indirectly summarize and conclude three things
Reward model training is its own large task, independent of pretraining or chat model training
There is a class of preference models which are publicly available as well, though it seems not the LLAMA reward/preference models
GPT-4, which is not a reward or preference model, still performs fairly well as one, which leaves open the question if specific preference models are needed in the future.
This subsection concludes similarly to Section 2, showing that the reward models were still learning after each batch of human preference ratings, albeit a bit slower each time, meaning there the upper bound of preference/reward capture is still unknown.
Iterative Fine-Tuning#
This subsection is the densest, both in terms of mathematics and unique approaches taken to shape this model. This is also evident in the amount of calendar time taken for just this stage, Fine-tuning for this model took over 3 months, leading to 5 different RLHF models (V1 through V5) with changes made during the process for each successive model.
PPO and Rejection Sampling RLHF#
There were two methodologies used: Proximal Policy Optimization (PPO) and Rejection Sampling fine-tuning. In short, Rejection Sampling is a breadth-first approach that samples multiple responses from the LLM and keeps the best one. PPO samples one response per prompt before updating the policy. Notably, the LLAMA 2 authors discuss that their use of rejection sampling is relatively novel, taking more time to explain it than they do for the PPO method. A fuller explanation between the two is in section 3.2.3.
Note
Much more can be written about PPO and Rejection Sampling in a fine-tuning context, and I likely will in the future. For now I suggest reading Hugging Face’s various courses
Ghost Attention#
Another novel training technique proposed is Ghost Attention. The desire is for models to follow a set of instructions over multiple turns, for instance, “You enjoy tennis”. The way it’s implemented is simple, for multi-turn conversations in training, the instruction string is just prepended to the front. The authors then use the aforementioned strategies to reinforcement train the model.
For some reason, PPO is then mentioned again in this section. The authors also provide the actual penalty term, notably being a piecewise function with a safety threshold.
Human Evaluation#
The most interesting part to me is Meta both stating Human ratings are the gold standard for judging models, and then having two sections that discuss how humans evals weren’t perfect. Both the unreliability of human judgment and that the human evals were limited for reasons. It’s still fascinating how these systems, even with all the time and expense that goes into them, still require a great deal of human evaluation to fully understand, and even then there are doubts.
Section 4 - Safety#
The first thing that’s notable is how long this section is. It’s as long as the fine-tuning section, which again highlights how much work Meta put into just the safety elements of this model.
Reading tip
It may be easier to read this section first before trying to fully understand Section 3. The fine-tuning section is a bit dense and doesn’t include many examples. The safety section revisits the fine-tuning ideas, such as RLHF, and shows many examples to make things more concrete.
This section goes over a number of points from training methods such as safety RLHF, to model characteristics such as prompt refusal, to red teaming, to again human evaluation.
However, the most interesting content is in the Appendix. Specifically section A.4. This section talks about the tension between safety and helpfulness. In section A.4.5, a table shows a single prompt with different responses across the safety scale, with the corresponding reward model score and a helpful score. This one table provides the most concrete view of the end-to-end training process, as in all previous sections the methodology and outputs of the training process, and reward models, are abstractly specified but without many examples.
Section 5 - Discussion#
The discussion section is more of a grab bag of topics. It talks about how human supervision could be eliminated, in favor of machine supervision with just human evaluation. There are two sections on how the model “auto learns” the temperature parameters, learning to be the right amount of creative or factual independent temperature. And then there are two sections of not specifically trained but learned useful behavior. Those are temporal understanding, and tool use.
The last two sections have to do with responsible release. In the context of open-sourcing the weights, these two sections are interesting, in that they lay out the more technical reasons why this model was open-sourced, and the limitations and ethical considerations in context. Mark Zuckerberg provides some additional context about these considerations in an interview as well.
Section 6 and 7 - Related Work and Conclusions#
These two sections are also a grab bag of topics. The first I’ll note here are Figure 5.1.
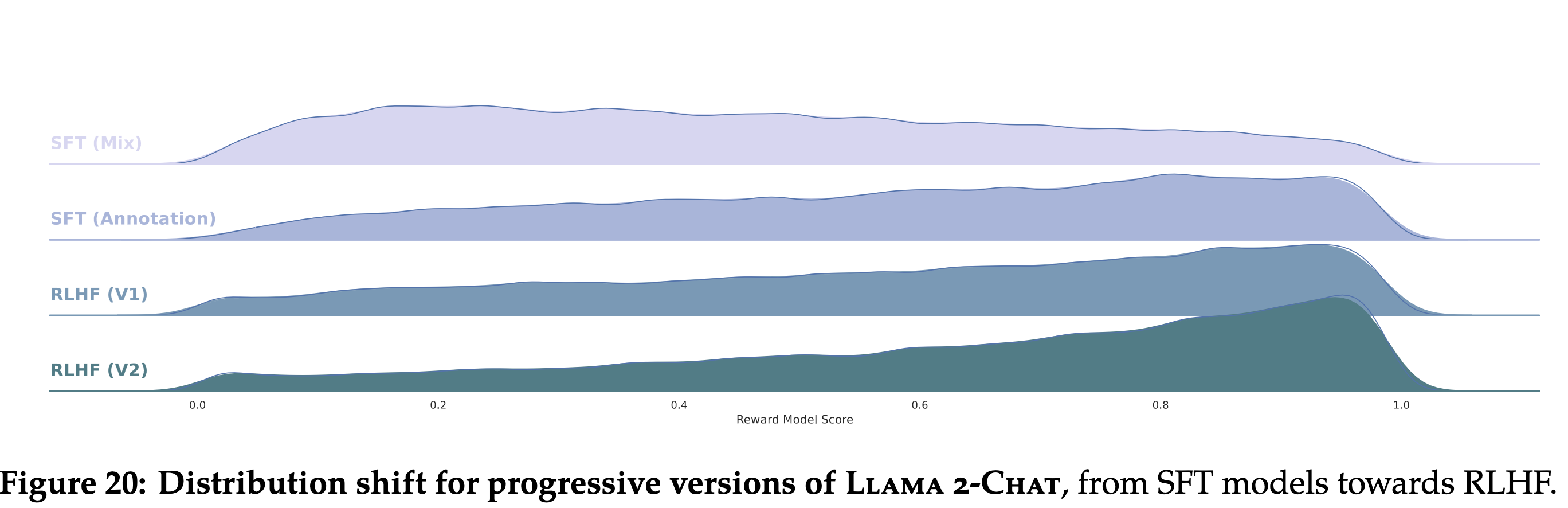
Fig. 70 A good summary image showing LLAMA 2’s progress over different training phases.#
The authors label the x-axis as ‘reward’, but it is unclear whether this refers to the helpfulness model reward, safety reward, or a combination Nonetheless, it’s a good overall view of how each aspect of training changes the distribution. Annoyingly, they stop at RHLF v2, it’d be interesting to see where the final model ended up.
The second interesting discussion is tool use. LLAMA 2 wasn’t trained explicitly for tool use but seems to have learned how to use the appropriate one in a zero-shot context.
The rest of this section, and the conclusion, cover topics that were touched such as replacing human reinforcement with AI reinforcement.
What to do from here#
This depends largely on your interest, I’ll provide some broad suggestions here.
Deploy your own model locally. Aside from the direct novelty of having your own AI agent, you can test out different parameter size models, or change hyperparameters. Trying these experiments will help you get a sense of how these changes affect the model responses, end-to-end inference duration, etc.
Try some of the downstream models that use LLAMA 2 as a base, understand how they’re trained, how they’re different. An example is https://ollama.ai/ which provides an uncensored model that removes the safety guardrails.
Read the references for the LLAMA2 paper. It provides references to many state-of-the-art techniques, such as training data contamination detection.
References#
LLAMA 2 Main Website - Meta’s main website highlighted various parts of the model, its usage, and testing
LLAMA 2 Paper - The full text of what we summarized here
OLLAMA - An version of LLAMA that has been unaligned to remove safety controls
Grouped Query Attention - An explanation of grouped query attention. It includes a nice diagram of various attention architectures, marking it easier to understand all attention mechanisms.