
Language Model Systems#
TL;DR
Language Models and Language Model Systems are different.
A language model (LLM) on its own has several limitations.
You can combine a model with other components.
Language model system = LLM model + other components
Language model systems:
Can address limitations inherent in LLMs
Improve usability and functionality
Provide more security and safety
Several architectures are growing in popularity for improved quality of output:
Generation with extra processing layers
Retrieval Augmented Generation (RAG)
Tool Use
LLM System Architecture is a fast-moving space that is evolving quickly.
Tooling libraries, options, and services are a hot ecosystem.
New patterns are being introduced all the time.
Why Systems#
Websites today are awesome. You can watch movies on demand, share content with friends, and securely bank online. It wasn’t always like this though. The early internet solely involved text requests with text returned. There was no dynamic rendering, no input acceptance or storage, and overall, it was a simple, but limited, experience.

Fig. 35 How websites worked in 1990. You had a URL, someone had a file. HTML didn’t even exist yet.#
Over time, additional components were added to web applications to address shortcomings. This included adding databases for information persistence, code execution on both the server and client side, and common tooling and patterns that developers could use to build apps. That is, webpages became systems comprised of many different components.
It’s this modern ecosystem of tried-and-true patterns, off-the-shelf components, and common protocols that make the modern web both possible and easy to build, which is why web applications are now everywhere.
The Basic LLM#
The most basic LLM Architecture involves text in, and probabilistic text generation out.
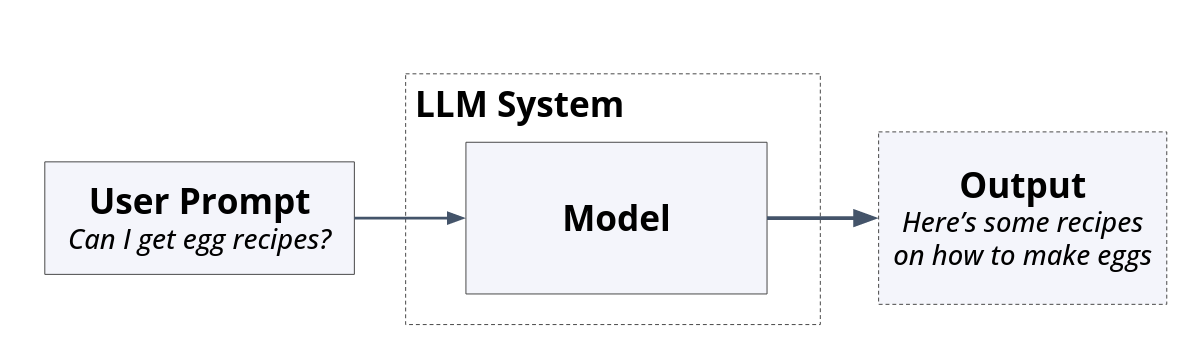
Fig. 36 Text goes in, and text comes out.#
Text In is an oversimplification
Technically, LLMs are “Token in” systems, with multimodal LLMs possessing the capability to ingest images and other media. They also are now able to generate multimodal outputs, such as audio.
However, for the purposes of this page in the guidebook, we’ll maintain the simplification, as current LLM systems seem to use text as their primary channel for interacting with other components. Multimodal models are becoming more common, but again, for the simplicity of this article, we’ll focus on text only for now.
Though text in -> text out is common, this architecture has challenges.
Models hallucinate facts quite readily.
The information trained in pretraining and fine-tuning goes out of date quickly.
Simple tasks, like addition, are challenging for LLMs.
Language Model Limitations#
Language models themselves have many limitations. Here are some of the ones that often cause challenges.
Out of Date Immediately - The “memory” of LLMs is limited to whatever was available at train time, and because large models take months to train, your model’s knowledge is out of date by the time training is finished.
Hallucinations and Lack of Citations - Most LLMs make up facts and even fake citations quite readily. It’s difficult to determine where the source material for a particular generation comes from just by the generation itself.
Unreliable Expensive Compute - Ask an LLM what 2+2 is, and you’ll spend a lot of compute not getting a reliable answer.
But computers 60 years ago could solve this problem with ease with basic binary addition.
Helpful and Hard to Control - The specific generation from LLMs is not typically known. This is both a feature and a bug. However, with some prompts or questions, we want to ensure the LLM is not too helpful, such as if prompted to provide passwords or secrets.
LLM System Architectures#
To mitigate these limitations, language models can be paired with other components to build LLM Systems. This, hopefully, makes the total output better for the user than what a pure LLM is able to provide. These include additional processing layers, external datastores, the ability to call other programs, and more. The entire ecosystem is being rapidly built out to enable faster development and better experiences, above and beyond improvements in the language model itself.
References#
GitHub Guide to LLM Architectures - A good walkthrough of how to think about LLM Architectures.
A16z Reference to LLM Architectures - A VC guide to LLM system components and patterns.
Extra Processing Layers#
In manufacturing, after producing a part, there is often a quality department that checks everything is correct. The same can be done with LLM generation. Outputs can be inspected by additional components. If they don’t pass inspection, they fail.
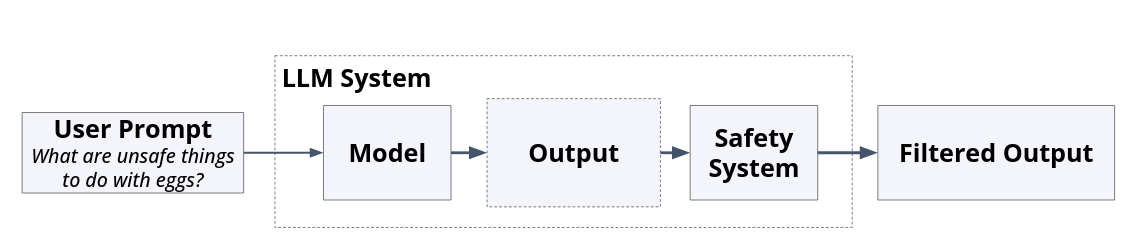
Fig. 37 Inputs and outputs could be scanned by additional layers to guide system outputs outside the bounds of the LLM.#
This could be as simple as keyword term checks, or as sophisticated as another LLM that parses the outputs of a generation LLM. This idea is similar to reward models. This reward model could be placed after response generation to assess the safety of the model’s response. For example, see page 61 of the LLAMA2 Technical report where a reward model scores the safety of a response. If it’s below a certain threshold, the response could be blocked.
References#
LLAMA Guard - An open-weight LLAMA class model designed specifically for prompt and response safety classification.
Lakera’s Gandalf - A fun game that demonstrates AI security. Towards the later levels, there’s both a generation LLM and a “guard” LLM that is evaluating responses for a password that is meant to be a secret.
Retrieval Augmented Generation#
Retrieval Augmented Generation, or RAG, is an architecture where the LLM is provided access to an external datastore. This external datastore is preloaded with relevant documents, or text snippets that have been mapped into an embedding space. When the user queries the LLM system, the user query is also mapped to the same embedding space. The user query is then augmented with one or more text snippets before being passed to the LLM. Then, as usual, the LLM generates a response which is returned to the user.
RAG is an open-book test#
Pretend you’re in a biology class taking a test. The exam question is, What can you tell me about frogs in North America? You first need to understand the question.
If you answer from memory, then that would be a plain language model. You’re parsing the question using your language skills, and you’re only utilizing the “compressed” information you remember in your head. This would be equivalent to a closed-book test where you have no references.
Now consider if this was an open-book test. You’d use your language skills to parse the question. However, you’d then find the relevant passages in the book, before combining your language skills with the passages from the book to provide an answer.
RAG Architecture#
RAG adds these additional components:
A document chunker and ingester.
A vector DB for storing texts and embeddings.
The retrieval augmentation mechanism itself.
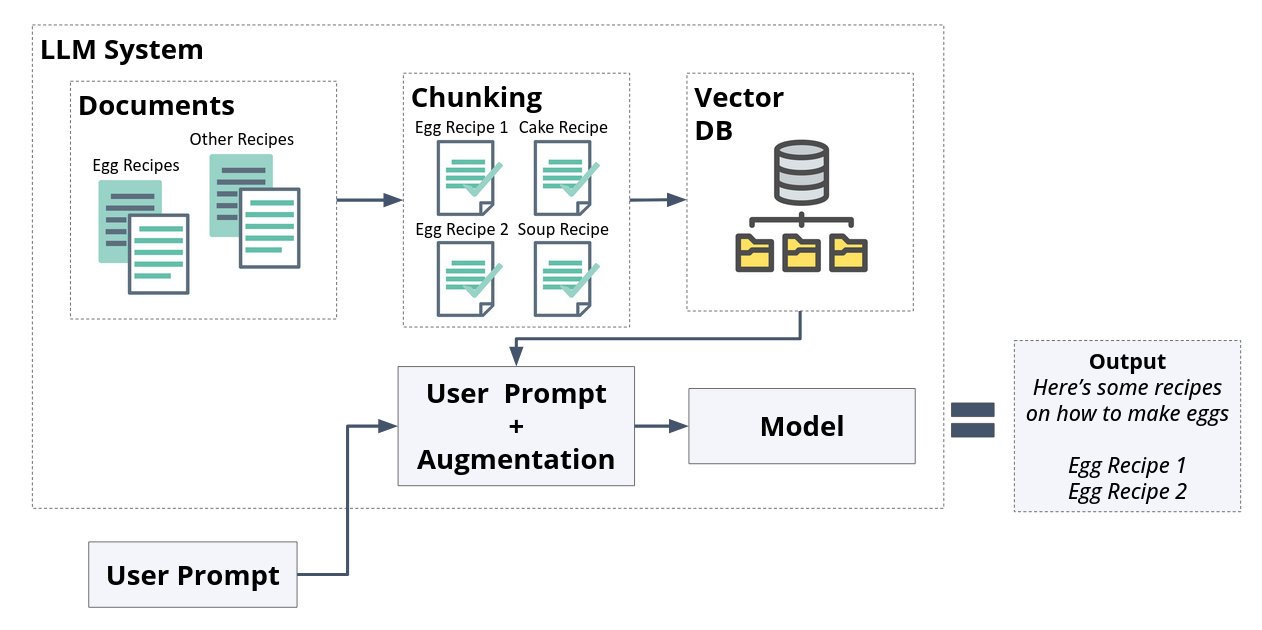
Fig. 38 A RAG system, with an embedding and retrieval pipeline.#
RAG Benefits#
RAG systems provide:
Easy data swaps and refreshes - As new documents and texts become relevant, they’re easily added to the embedding DB. No retraining is required.
Grounding - RAG can reduce hallucinations by providing direct text for quoting and/or biasing the text generation using the prompt itself. https://techcommunity.microsoft.com/t5/fasttrack-for-azure/grounding-llms/ba-p/3843857
Cited references - RAG gives LLM systems a way to cite an answer’s source, facilitating human verification.
References#
Building a RAG web app with Ollama - A nice self-contained guide showing a self-contained RAG app.
Llama Index’s Docs - Shows the API and how RAG embeddings are synthesized into prompts.
Chunking Strategies for embedded documents - Guidance for a design choice that needs to be made when adding new documents.
A Python implementation of RAG - A tutorial that includes a fair bit of hands-on code.
RAG guide from embedding provider Pinecone - Another code-first tutorial with great diagrams and breakdown.
Local RAG Implementation using Mistral - An all-in-one self-contained notebook.
Tool Use#
Tool use provides an LLM system the capability to include other types of computation in the process of final answer generation.
This could be:
Calling APIs to access current information, such as the weather.
Storing intermediate outputs in computer memory, and other data stores (maybe even a RAG system).
Code Execution environments.
Writing outputs to long-term storage when prompted by the user, for instance, saving an output to a document.
Tool Use is Function Calling
Tool Use is synonymous with Function Calling, which is the name OpenAI and Google use in their APIs.
Tool Use Analogy#
Let’s say you’re asked to perform the calculation 223423 * 23421.
You could do this yourself, but you’d probably get it wrong.
To ensure you get it right, you could use a basic tool,
such as a calculator,
even an old one from 1970.
Now ask an LLM to do the same calculation.
It too will probably get it wrong,
even though LLMs themselves run on the most modern compute available!
Here’s what ChatGPT and LLAMA2 return,
compared to Python.
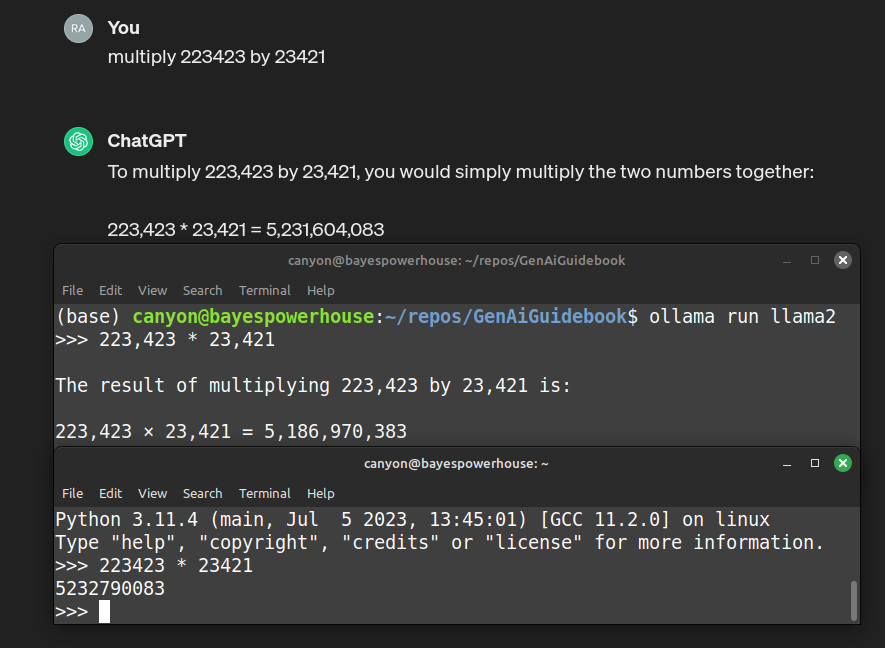
Fig. 39 ChatGPT and LLAMA2 getting basic multiplication wrong, while Python, and a basic calculator, will get it right every time.#
What we can do is give an LLM access to a tool, such as a calculator or Python. This way, when an LLM is asked to perform a basic computation, instead of trying itself, it can delegate to another program.
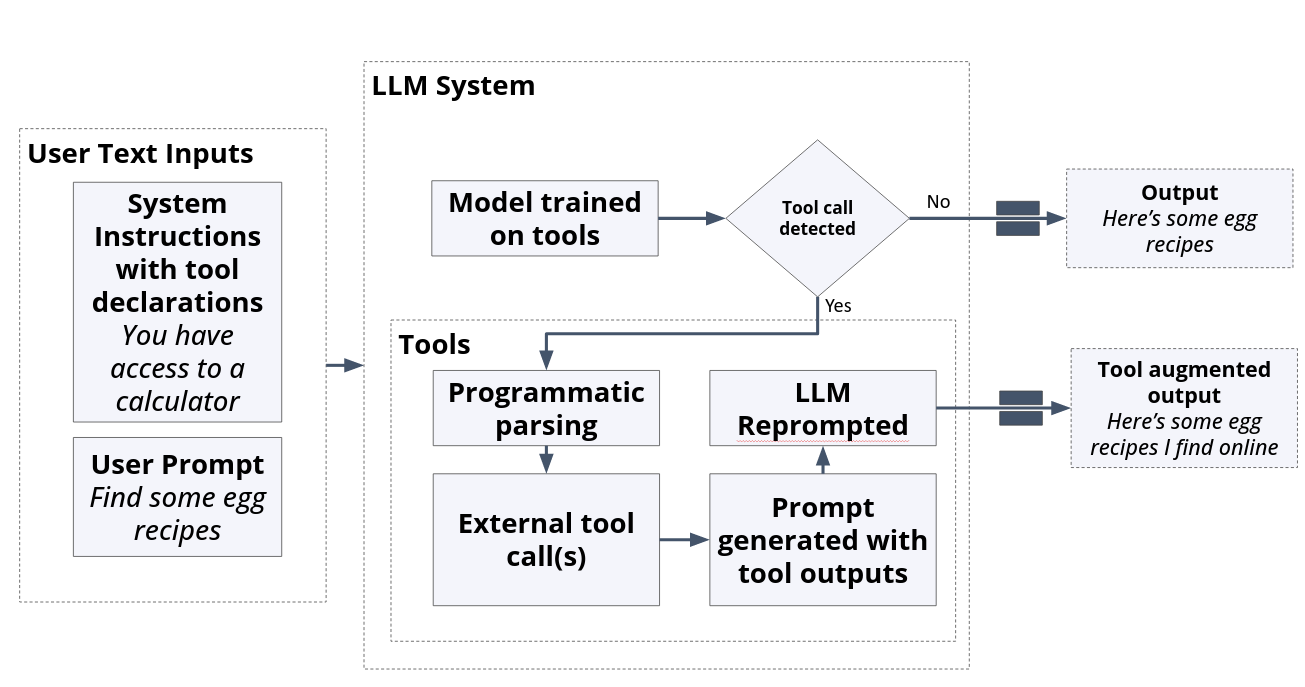
Fig. 40 Flow diagram of a typical tool-enabled LLM System. Note how the LLM is prompted twice or more in this flow.#
LLMs don’t run the tools themselves. Instead, when the LLM predicts that a tool might be appropriate, it generates an output string that indicates a “request” to use an external tool. Then, the LLM system defers the computation and information retrieval to methods that are superior to probabilistic generation from fixed weights. LLMs can handle natural language parsing and generation while delegating tasks it’s inferior to other programs.
Tool Use in Practice#
Here is an example input and output string from Langchain where a calculator tool is used. Note the specific input and output response pair.
Question: What is 37593 * 67?
...numexpr.evaluate("37593 * 67")...
This output is not returned to the user directly. It is captured by the LLM System. The text output is then sent to numexpr, for evaluation.
Here’s the abbreviated pseudo code; the entire code module is here in LangChain
import numexpr
text_match = re.search(r"^```text(.*?)```", llm_output, re.DOTALL)
if text_match:
# Numexpr is the external tool that programmatically parses text into python calculations
numexpr_calculation = numexpr.evaluate(text_match)
answer = prompt_llm_with_tool_result(numexpr_calculation)
else:
return llm_output
It is infeasible that LLMs be retrained every day to understand what the weather is that day. Yet the question “What is the weather today?” is a common one, retrieving the weather via API is trivial.
For that, you’ll find tools for weather APIs, YouTube, arbitrary Python execution, and many search engines
Not Always Reliable#
To achieve this behavior, The LLM is pre-prompted, either fine-tuned or preprompted with a few-shot examples showing the format. Here’s an example from the Langchain source code. However, like all things LLM, tool use is dependent on model text/token generation which by design isn’t always repeatable or consistent. And even if a tool is called, there isn’t a guarantee it’s called with the right arguments or parameters, which also leads to wrong or inconsistent outputs. This is especially jarring if coming from a programming perspective where tool or function calls are essentially guaranteed. From personal experience and reading from others, tool use is often brittle, and heavily dependent on the model itself, prompt, and the tools. Nonetheless, it’s a powerful capability that will improve over time.
References#
Langchain docs on tools - Shows how these agents work and how to define custom tools.
HuggingFace tool use training - A guide on finetuning a model to be good at tool use.
Tutorial showing LLAMA 2 tool usage - An applied guide with examples of LLAMA 2 using tools.
Langchain Docs - Langchain search tool implemented in Github.
OpenAI docs for Function Calling - OpenAI’s API specifications for function calling.