
Towards Comprehensive Risk Assessments and Assurance of AI Based Systems#
Rather than focus on models itself this paper focuses on terminology, risk asessment methodologies from various fields, and proposal for a risk assessment framework that fits modern AI systems.
The main takeaways for me were
A detailed discussion on how AI safet and risk language is conflated causing confusion
Why transferring risk assessment frameworks from mechanical, software, and cybersecurity frameworks don’t quite fit AI systems
A proposal for risk assessment framework specifically for multi model GenAI systems
I chose to read this paper as the terminology around AI safety is fairly confusing. I learned about the paper from OpenAI’s red teaming network announcement, in a footnote where they echo language such as Red Teaming shifts subtly in the context of AI, and cited this paper.[1]
The main takeaways for are in Section 2, where the need for precise languge and a dedicated risk assessment framework is motivated, and Section 4 where the risk assessment frameowrk is detailed. Section 3 highlights pitfalls in existing methods that are often taken from other fields and applied in the context of AI.
Executive Summary and Introduction#
Both the executive summary and introduction summarize the paper. We won’t do that again here as I’ve already summarized my takeaway aboves.
A notable line is this one
More broadly, we hope it [the paper] appeals to members of the public who wish to understand the prospects of AI assurance and safety in the midst of marketing hype and exaggerated commercial messaging
It’s great to see honest AI writing come out that are targeted to non researchers. The structure of this writing as white paper with an executive summary and key takeaways serves this intended audience quite well.
Section 2 - Distinguishing Value Alignment, Safety, and Risk#
This is the key section in the paper as it directly highlights the conflation of language.
Section 2.1 explains how Value Alignment isn’t Safety. Value alignment is in AI is a system requirement focused on how a system should act, and also is subjective. Safety is a broader idea, focused on potential harms and reducing the the frequency of such harms.
Section 2.2 also breaks apartment terminology that is often conflated in the AI context, specifically detailing the terms
Hazards - Conditions that can result in a system producing or undesirable effects
Risks - The probability of hazards occuring
Threats - A subset of hazards more specific to security where an undesirable event affects system integrity
There’s a final secion that summarizes three more terms. specifically errors, faults, failures, and Failure modes.
Personal Note#
This section was the most confusing to me, not because the writing was poor but because of how quickly I’ve become indoctrinated to the \(alignment=safety\) view of thinking. At first blush it seems obvious, an AI that’s aligned to what a “good” human would do is safe right? But it doesn’t take much probing for this to fall apart. A good example is from the LLAMA 2 Paper and Model Deep Dive we covered, which splits helpfulness and safety into it’s own two reward models. Meta does this because a model that is helpful to one person doesn’t always produce a safe outcome for a group of people as a whole. The common example is asking an LLM for instructions on how to make a bomb. In this case an AI that’s aligned to the user intent, is not safe for non users, already breaking apart the equality between alignment and safety. However this paper highlights how the rift is even larger than that. An aligned AI, even one that doesn’t say anything harmful, still has a number of safety concerns, a common example here being job safety for entire classes of workers.
Section 3 - Pitfalls in Existing Adoptions and Appraoches#
Safety as a field, and more generall the study of failing systems, of study is not new. The author brings in systems from the domain of mechanical and systems engineering, as well as software engineering, and highlights why their frameworks of Failure Mode and Effects, software ISO 26262:2018 definitions, and cybersecurity bug bounty processes are inadequete. In summary the sheer scale and complexity of what modern AI systems can do, the inability to partition their functionality, non determinism of function, and the subjectivity of the harm in final output produced, belie these established fields.
The disconnect largely has to do with the basic difference in how these systems function. In mechanical engineering parts have one specific function, whether it’s say a bolt holding two pieces of metal together, or an O-ring that separates two flammable materials together. In the mechanical world parts experience random failure, one that often is well characterized. It’s also very clear how a failure of this part could affect the rest of the system. This narrow scope of function and (hopefully) well characterized frequency is th basis for Failure Mode and Effects diagrams.
In software the behavior is deterministic, and the gap between systems requirement and safety is much tighter. When a piece of software is written by humans it’s very clear what the intended outcome is, trivial to measure if it doesn’t happen, and pieces of the system can be isolated.
Section 3.3 in particular details why the existing systems are inadquete and motivates the Section 4.
Section 4 - Unifying Risk Assessment and Safety Justification#
This section proposes a new taxonomy and framework to assess GenAI risks. It’s an extension of a framework used in Autonomus driving. The section is quite detailed and explains each part in depth. The two figures summarize the concepts quite well.
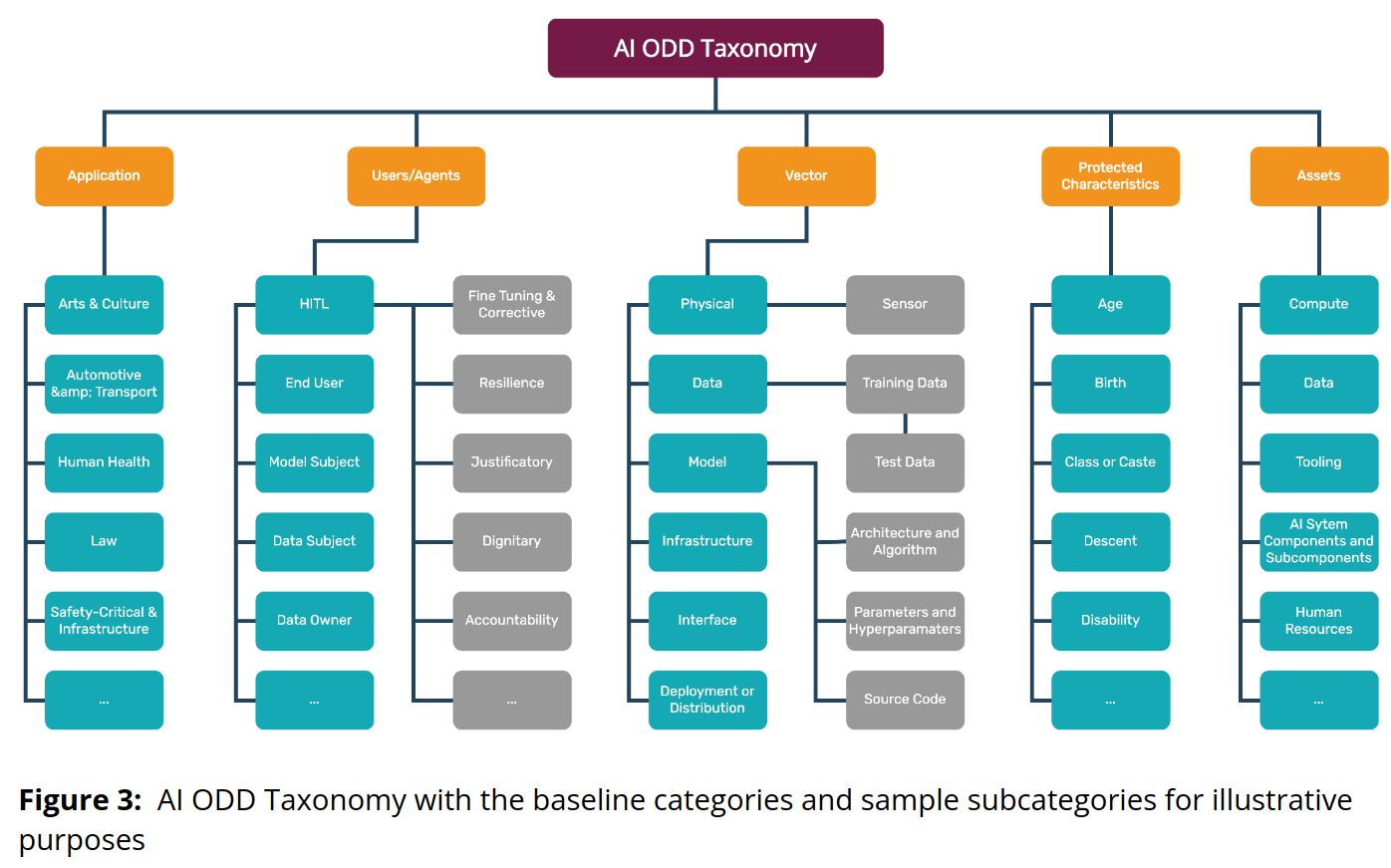
Fig. 74 The various dimensions of which the framework can be applied#
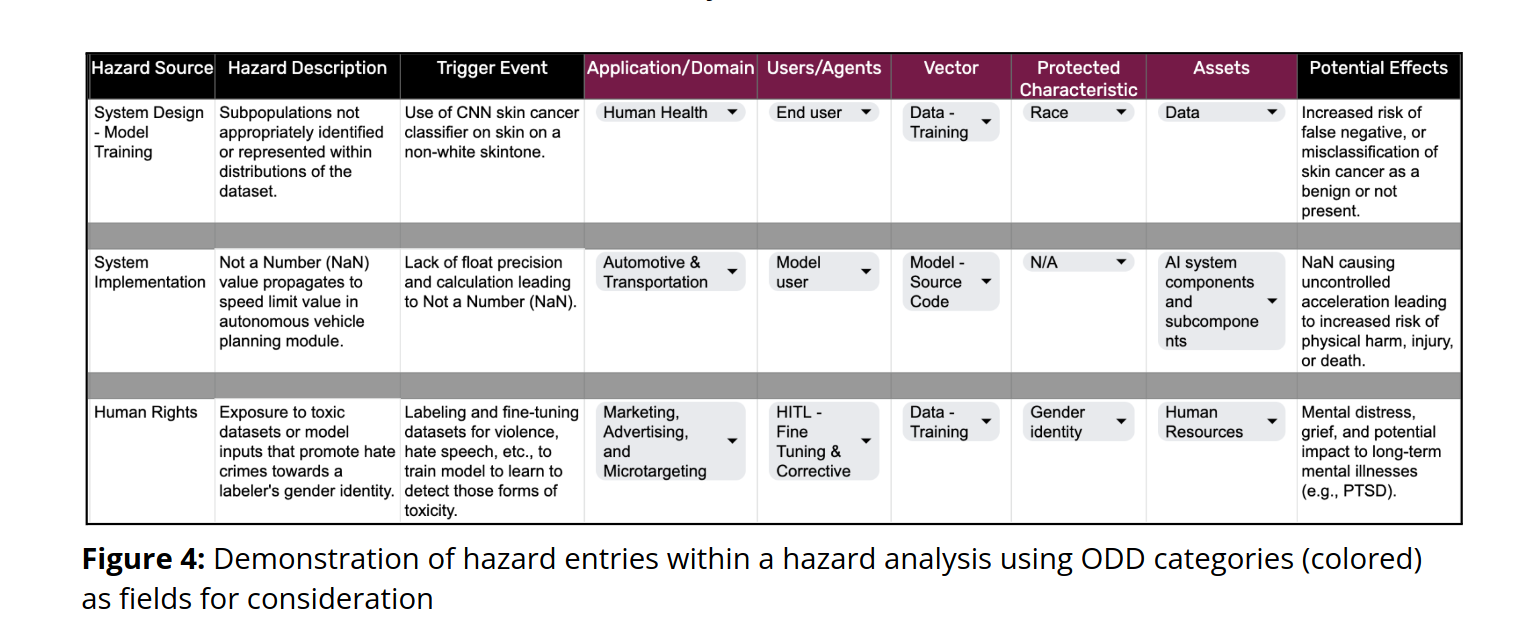
Fig. 75 An example of the framework and how it could look in practice.#
The examples shown don’t just concern the end generation, but all parts of the AI lifecycle, from computational training, reviews in the RLHF process, etc. Personally it’s clear to me this author has practical experience for no other reason than they show how this would fit into a spreadsheet. You’ll be surprised how many decisions are made in leading edge companies based on the contents of a spreadsheet, and even more surprised at how effective they are.
Section 5 - Conclusive Remarks#
The author again highlights how AI alignment, meaning the LLM to hte user is not the primary challenge, but terminology alignment is. With aligned terminology it becomes more clear what has been tested and what’s not. The author then discusses the benefits of the framework they propose and how it overcomes the limitations of other frameworks.
References#
Trail of Bits Paper - The source of the summarization above.