
Basic LLM Pretraining#
TLDR
We train a small LLM from scratch both to
Show how to build an LLM
Build a small LLM we’ll pretrain later
Use our own implementations of
DataLoader and tests
Training Loop implemented in this notebook
Reinforcement learning won’t work well directly on an LLM that is fully random. With LLMs the action and state space is large and the rewards are sparse. However unlike Ice Maze or other RL domains, LLMs are heavily trained before RL is applied through pretraining. Their behavior is not totally random at the start, but already shaped by a large amount of data and training cycles
Making a Super Tiny Model#
Instead of using an existing open weights LLM we’re still going to pretrain our own LLM for a couple of reasons. This is because we want
A super tiny model - Open weight LLMs are still often in the hundreds millions of parameters, requiring at least a GPU to train quickly.
A super tiny tokenizer/action space - Open weight LLMs have tokenizers that are 32k or more. To make later RL examples efficient we want
Full transparency - We can never be sure what an open weight LLM was trained on, making it impossible to tell if future behavior came from our data, our training, or the model creators.
By training our own model we can make it really small and specialize it to emit basic completions. The model’s purpose will be memorize a simple short sequences, both to make training extremely fast, and also so changes to be behavior are obvious and traceable.
Imports#
import torch
from torch.utils.data import DataLoader
from torch import nn
import os
import matplotlib.pyplot as plt
from cleanllm.data import data_loader
from cleanllm import minimal_llm
from cleanllm import pretrain
from cleanllm.pretrain import top_k_predictions
import seaborn as sns
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
Data#
This is the corpus we’re going to train on. By modern LLM standards its quite small. Typically it is desirable for LLMs to complete a wide variety of texts. However this is not what we want in this case. To show that our future RL is effective we want to
Know what the input data is so we can separate emergent behavior from training data
Provide a bit of variety but not too much so our RL can converge
Focus on a small set of data its easy to train on and even easier to see how RL shifts a models behavior.
{"input": "ravin likes ice cream"}
{"input": "ravin likes cookies"}
{"input": "ravin likes pizza"}
{"input": "ravin likes donuts"}
{"input": "ravin likes soda"}
{"input": "ravin likes salad"}
{"input": "ravin likes apples"}
{"input": "ravin likes lettuce"}
{"input": "sam likes salad"}
{"input": "sam likes water"}
{"input": "sam likes sandwiches"}
{"input": "sam likes carrots"}
Tokenizer#
LLMs need text to be tokenized before they can be trained on it. In our corpus we use S as the start token and E as the end token. This particular tokenizer is a character level tokenizer to keep things simple. We also use a restricted vocabulary on purpose to keep the the model small to make this model easy to run on consumer hardware.
For our LLM we’ll use only lower case characters plus space “ “. Well also add in three special tokens, often referred to as control tokens
p - Padding, used during training to maintain fixed array sizes
S - Start of sequence
E - End of sequence, specifically used during inference to stop sampling
tokenizer = data_loader.CharacterTokenizer()
tokens = tokenizer.encode("PSE abcdefghijklmnopqrstuvwxyz")
tokens[:12]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
This is what a string from our training data looks like when its encoded.
tokenizer.encode("Ssam likes carrotsE")
[1, 22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 6, 4, 21, 21, 18, 23, 22, 2]
Data Loading#
To train a model we’ll need to load and tokenize many samples. During data loading we need to chunk our data to predict next token and set a batch size for training. Our data_loader class handles this for us.
batch_size = 32
context_length = 20 # Set to be longer than sequences in text
food_dataset = data_loader.PeopleDataset(tokenizer, max_context_length=context_length, eos_oversample_factor=1)
train_loader = DataLoader(food_dataset, batch_size=batch_size, shuffle=True)
# Validation is reusing the same dataset. This is not typical. Read below
validation_dataset = data_loader.PeopleDataset(tokenizer, max_context_length=context_length)
validation_dataloader = DataLoader(food_dataset, batch_size=batch_size)
for row in train_loader:
print(row)
[tensor([[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 19, 12, 29, 29, 4,
0, 0],
[22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 17, 7, 26, 12, 6, 11,
8, 22],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 7, 18, 17, 24, 23,
22, 0],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 4, 19, 19, 15, 8,
22, 0],
[ 1, 22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 15, 4, 7, 0, 0,
0, 0],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6, 21,
8, 4],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 22, 4, 15, 4, 7,
0, 0],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 22, 18, 7, 4, 0,
0, 0],
[ 1, 22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 26, 4, 23, 8, 21, 0, 0,
0, 0],
[ 1, 22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 17, 7, 26, 12, 6,
11, 8],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 6, 18, 18, 14, 12,
8, 22],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6,
21, 8],
[ 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6, 21, 8,
4, 16],
[ 1, 22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 6, 4, 21, 21, 18, 23, 22,
0, 0],
[ 1, 21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 15, 8, 23, 23, 24,
6, 8]]), tensor([[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 19, 12, 29, 29, 4, 2,
0, 0],
[ 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 17, 7, 26, 12, 6, 11, 8,
22, 2],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 7, 18, 17, 24, 23, 22,
2, 0],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 4, 19, 19, 15, 8, 22,
2, 0],
[22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 15, 4, 7, 2, 0, 0,
0, 0],
[ 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6, 21, 8,
4, 16],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 22, 4, 15, 4, 7, 2,
0, 0],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 22, 18, 7, 4, 2, 0,
0, 0],
[22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 26, 4, 23, 8, 21, 2, 0, 0,
0, 0],
[22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 22, 4, 17, 7, 26, 12, 6, 11,
8, 22],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 6, 18, 18, 14, 12, 8,
22, 2],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6, 21,
8, 4],
[25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 12, 6, 8, 3, 6, 21, 8, 4,
16, 2],
[22, 4, 16, 3, 15, 12, 14, 8, 22, 3, 6, 4, 21, 21, 18, 23, 22, 2,
0, 0],
[21, 4, 25, 12, 17, 3, 15, 12, 14, 8, 22, 3, 15, 8, 23, 23, 24, 6,
8, 2]])]
If we decode a sample we see a a phrase from our corpus. The P is a padding token so we can keep the input sequence the same length.
tokenizer.decode(row[0][0])
'Sravin likes pizzaPP'
Model Initialization#
From here we set the model parameters. This model is around 100k oarameters in size, the choice of these parameters came various experiments and iterations to find the smallest model that would somewhat reliably predict our data.
vocab_size = 30 # 26 letters + space + pad, sos, eos
d_model = 16
nhead = 4
num_layers = 6
dim_feedforward = 256
dropout=.8
model = minimal_llm.TransformerDecoderModel(
vocab_size, d_model, nhead, num_layers,
dim_feedforward,
context_length=context_length,
pad_id=tokenizer.pad_id,
dropout=dropout
).to(device)
model.get_total_params()
107814
print(model.tok_embedding)
Embedding(30, 16)
Sampling before Training#
Before we train the model we can check its initial state by sampling. Since the model weights are random we can expect random characters which is what we get. In addition to tokens we also keep the probabilities of each token and the logits across the entire token vocabulary. This will be needed later for reinforcement learning.
prompt = "ravin likes"
initial_output = model.sample(tokenizer, prompt, max_completion_len=20, device=device)
print(initial_output.completion_log_probs.shape)
print(initial_output.completion_logits.shape)
initial_output.completion
torch.Size([20])
torch.Size([20, 30])
'sScesss rcakyssrxapi'
initial_output.text
'ravin likessScesss rcakyssrxapi'
Training loop#
Now we can train the weights. On a 2024 M4 Macbook this takes about 5 minutes.
# Training
num_epochs = 5000
lr = 1e-5
# Reinitialize model each time
model = minimal_llm.TransformerDecoderModel(
vocab_size, d_model, nhead, num_layers,
dim_feedforward, context_length=context_length,
pad_id=tokenizer.pad_id
).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=tokenizer.pad_id, label_smoothing=0.05)
losses, val_losses = pretrain.train_model(model,
train_loader,
num_epochs,
device,
val_loader=validation_dataloader,
criterion=criterion,
print_every=100,
checkpoint_every_n_epochs=100,
checkpoint_dir="./temp/single_stage")
# losses, val_losses = pretrain.train_model(model, weighted_dataloader, num_epochs, device)
2025-08-12 20:14:17,144 - INFO - Starting training...
2025-08-12 20:14:21,402 - INFO - Epoch [100/5000], Batch [1/1], Loss: 1.2554 Avg Val Loss: 1.1120 Time: 0.04
2025-08-12 20:14:21,403 - INFO - Saving Checkpoint 99
2025-08-12 20:14:21,454 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_99.pt
2025-08-12 20:14:25,568 - INFO - Epoch [200/5000], Batch [1/1], Loss: 0.8146 Avg Val Loss: 0.6614 Time: 0.04
2025-08-12 20:14:25,568 - INFO - Saving Checkpoint 199
2025-08-12 20:14:25,616 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_199.pt
2025-08-12 20:14:29,575 - INFO - Epoch [300/5000], Batch [1/1], Loss: 0.6013 Avg Val Loss: 0.5421 Time: 0.05
2025-08-12 20:14:29,575 - INFO - Saving Checkpoint 299
2025-08-12 20:14:29,626 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_299.pt
2025-08-12 20:14:33,485 - INFO - Epoch [400/5000], Batch [1/1], Loss: 0.5774 Avg Val Loss: 0.5016 Time: 0.04
2025-08-12 20:14:33,486 - INFO - Saving Checkpoint 399
2025-08-12 20:14:33,536 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_399.pt
2025-08-12 20:14:37,413 - INFO - Epoch [500/5000], Batch [1/1], Loss: 0.5196 Avg Val Loss: 0.4841 Time: 0.04
2025-08-12 20:14:37,413 - INFO - Saving Checkpoint 499
2025-08-12 20:14:37,463 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_499.pt
2025-08-12 20:14:41,450 - INFO - Epoch [600/5000], Batch [1/1], Loss: 0.5226 Avg Val Loss: 0.4798 Time: 0.04
2025-08-12 20:14:41,450 - INFO - Saving Checkpoint 599
2025-08-12 20:14:41,503 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_599.pt
2025-08-12 20:14:45,441 - INFO - Epoch [700/5000], Batch [1/1], Loss: 0.5002 Avg Val Loss: 0.4762 Time: 0.04
2025-08-12 20:14:45,442 - INFO - Saving Checkpoint 699
2025-08-12 20:14:45,494 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_699.pt
2025-08-12 20:14:49,410 - INFO - Epoch [800/5000], Batch [1/1], Loss: 0.4970 Avg Val Loss: 0.4739 Time: 0.04
2025-08-12 20:14:49,411 - INFO - Saving Checkpoint 799
2025-08-12 20:14:49,465 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_799.pt
2025-08-12 20:14:53,331 - INFO - Epoch [900/5000], Batch [1/1], Loss: 0.4986 Avg Val Loss: 0.4724 Time: 0.04
2025-08-12 20:14:53,332 - INFO - Saving Checkpoint 899
2025-08-12 20:14:53,384 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_899.pt
2025-08-12 20:14:57,277 - INFO - Epoch [1000/5000], Batch [1/1], Loss: 0.4913 Avg Val Loss: 0.4707 Time: 0.04
2025-08-12 20:14:57,277 - INFO - Saving Checkpoint 999
2025-08-12 20:14:57,330 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_999.pt
2025-08-12 20:15:01,235 - INFO - Epoch [1100/5000], Batch [1/1], Loss: 0.4772 Avg Val Loss: 0.4696 Time: 0.04
2025-08-12 20:15:01,235 - INFO - Saving Checkpoint 1099
2025-08-12 20:15:01,288 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1099.pt
2025-08-12 20:15:05,193 - INFO - Epoch [1200/5000], Batch [1/1], Loss: 0.4731 Avg Val Loss: 0.4685 Time: 0.04
2025-08-12 20:15:05,193 - INFO - Saving Checkpoint 1199
2025-08-12 20:15:05,246 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1199.pt
2025-08-12 20:15:09,226 - INFO - Epoch [1300/5000], Batch [1/1], Loss: 0.4802 Avg Val Loss: 0.4692 Time: 0.04
2025-08-12 20:15:09,226 - INFO - Saving Checkpoint 1299
2025-08-12 20:15:09,280 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1299.pt
2025-08-12 20:15:13,182 - INFO - Epoch [1400/5000], Batch [1/1], Loss: 0.4820 Avg Val Loss: 0.4672 Time: 0.04
2025-08-12 20:15:13,183 - INFO - Saving Checkpoint 1399
2025-08-12 20:15:13,235 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1399.pt
2025-08-12 20:15:17,203 - INFO - Epoch [1500/5000], Batch [1/1], Loss: 0.4859 Avg Val Loss: 0.4664 Time: 0.04
2025-08-12 20:15:17,204 - INFO - Saving Checkpoint 1499
2025-08-12 20:15:17,257 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1499.pt
2025-08-12 20:15:21,164 - INFO - Epoch [1600/5000], Batch [1/1], Loss: 0.4770 Avg Val Loss: 0.4657 Time: 0.04
2025-08-12 20:15:21,164 - INFO - Saving Checkpoint 1599
2025-08-12 20:15:21,217 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1599.pt
2025-08-12 20:15:25,156 - INFO - Epoch [1700/5000], Batch [1/1], Loss: 0.4787 Avg Val Loss: 0.4656 Time: 0.04
2025-08-12 20:15:25,156 - INFO - Saving Checkpoint 1699
2025-08-12 20:15:25,212 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1699.pt
2025-08-12 20:15:29,171 - INFO - Epoch [1800/5000], Batch [1/1], Loss: 0.4753 Avg Val Loss: 0.4648 Time: 0.04
2025-08-12 20:15:29,171 - INFO - Saving Checkpoint 1799
2025-08-12 20:15:29,224 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1799.pt
2025-08-12 20:15:33,235 - INFO - Epoch [1900/5000], Batch [1/1], Loss: 0.4780 Avg Val Loss: 0.4645 Time: 0.04
2025-08-12 20:15:33,236 - INFO - Saving Checkpoint 1899
2025-08-12 20:15:33,290 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1899.pt
2025-08-12 20:15:37,212 - INFO - Epoch [2000/5000], Batch [1/1], Loss: 0.4756 Avg Val Loss: 0.4638 Time: 0.04
2025-08-12 20:15:37,213 - INFO - Saving Checkpoint 1999
2025-08-12 20:15:37,267 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_1999.pt
2025-08-12 20:15:41,163 - INFO - Epoch [2100/5000], Batch [1/1], Loss: 0.4827 Avg Val Loss: 0.4640 Time: 0.04
2025-08-12 20:15:41,163 - INFO - Saving Checkpoint 2099
2025-08-12 20:15:41,217 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2099.pt
2025-08-12 20:15:45,156 - INFO - Epoch [2200/5000], Batch [1/1], Loss: 0.4758 Avg Val Loss: 0.4631 Time: 0.04
2025-08-12 20:15:45,156 - INFO - Saving Checkpoint 2199
2025-08-12 20:15:45,208 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2199.pt
2025-08-12 20:15:49,179 - INFO - Epoch [2300/5000], Batch [1/1], Loss: 0.4802 Avg Val Loss: 0.4631 Time: 0.04
2025-08-12 20:15:49,179 - INFO - Saving Checkpoint 2299
2025-08-12 20:15:49,231 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2299.pt
2025-08-12 20:15:53,224 - INFO - Epoch [2400/5000], Batch [1/1], Loss: 0.4610 Avg Val Loss: 0.4628 Time: 0.04
2025-08-12 20:15:53,224 - INFO - Saving Checkpoint 2399
2025-08-12 20:15:53,279 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2399.pt
2025-08-12 20:15:57,172 - INFO - Epoch [2500/5000], Batch [1/1], Loss: 0.4642 Avg Val Loss: 0.4625 Time: 0.04
2025-08-12 20:15:57,172 - INFO - Saving Checkpoint 2499
2025-08-12 20:15:57,228 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2499.pt
2025-08-12 20:16:01,131 - INFO - Epoch [2600/5000], Batch [1/1], Loss: 0.4734 Avg Val Loss: 0.4623 Time: 0.04
2025-08-12 20:16:01,132 - INFO - Saving Checkpoint 2599
2025-08-12 20:16:01,187 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2599.pt
2025-08-12 20:16:05,141 - INFO - Epoch [2700/5000], Batch [1/1], Loss: 0.4737 Avg Val Loss: 0.4619 Time: 0.04
2025-08-12 20:16:05,141 - INFO - Saving Checkpoint 2699
2025-08-12 20:16:05,195 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2699.pt
2025-08-12 20:16:09,105 - INFO - Epoch [2800/5000], Batch [1/1], Loss: 0.4736 Avg Val Loss: 0.4620 Time: 0.04
2025-08-12 20:16:09,105 - INFO - Saving Checkpoint 2799
2025-08-12 20:16:09,159 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2799.pt
2025-08-12 20:16:13,265 - INFO - Epoch [2900/5000], Batch [1/1], Loss: 0.4662 Avg Val Loss: 0.4618 Time: 0.04
2025-08-12 20:16:13,265 - INFO - Saving Checkpoint 2899
2025-08-12 20:16:13,315 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2899.pt
2025-08-12 20:16:17,395 - INFO - Epoch [3000/5000], Batch [1/1], Loss: 0.4698 Avg Val Loss: 0.4616 Time: 0.04
2025-08-12 20:16:17,395 - INFO - Saving Checkpoint 2999
2025-08-12 20:16:17,445 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_2999.pt
2025-08-12 20:16:21,347 - INFO - Epoch [3100/5000], Batch [1/1], Loss: 0.4591 Avg Val Loss: 0.4615 Time: 0.04
2025-08-12 20:16:21,348 - INFO - Saving Checkpoint 3099
2025-08-12 20:16:21,398 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3099.pt
2025-08-12 20:16:25,302 - INFO - Epoch [3200/5000], Batch [1/1], Loss: 0.4732 Avg Val Loss: 0.4619 Time: 0.04
2025-08-12 20:16:25,302 - INFO - Saving Checkpoint 3199
2025-08-12 20:16:25,354 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3199.pt
2025-08-12 20:16:29,344 - INFO - Epoch [3300/5000], Batch [1/1], Loss: 0.4644 Avg Val Loss: 0.4612 Time: 0.04
2025-08-12 20:16:29,345 - INFO - Saving Checkpoint 3299
2025-08-12 20:16:29,398 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3299.pt
2025-08-12 20:16:33,482 - INFO - Epoch [3400/5000], Batch [1/1], Loss: 0.4648 Avg Val Loss: 0.4613 Time: 0.04
2025-08-12 20:16:33,482 - INFO - Saving Checkpoint 3399
2025-08-12 20:16:33,538 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3399.pt
2025-08-12 20:16:37,462 - INFO - Epoch [3500/5000], Batch [1/1], Loss: 0.4673 Avg Val Loss: 0.4615 Time: 0.04
2025-08-12 20:16:37,462 - INFO - Saving Checkpoint 3499
2025-08-12 20:16:37,518 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3499.pt
2025-08-12 20:16:41,493 - INFO - Epoch [3600/5000], Batch [1/1], Loss: 0.4720 Avg Val Loss: 0.4611 Time: 0.04
2025-08-12 20:16:41,494 - INFO - Saving Checkpoint 3599
2025-08-12 20:16:41,546 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3599.pt
2025-08-12 20:16:45,871 - INFO - Epoch [3700/5000], Batch [1/1], Loss: 0.4668 Avg Val Loss: 0.4609 Time: 0.04
2025-08-12 20:16:45,872 - INFO - Saving Checkpoint 3699
2025-08-12 20:16:45,923 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3699.pt
2025-08-12 20:16:50,091 - INFO - Epoch [3800/5000], Batch [1/1], Loss: 0.4663 Avg Val Loss: 0.4607 Time: 0.04
2025-08-12 20:16:50,091 - INFO - Saving Checkpoint 3799
2025-08-12 20:16:50,144 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3799.pt
2025-08-12 20:16:54,174 - INFO - Epoch [3900/5000], Batch [1/1], Loss: 0.4681 Avg Val Loss: 0.4610 Time: 0.04
2025-08-12 20:16:54,174 - INFO - Saving Checkpoint 3899
2025-08-12 20:16:54,225 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3899.pt
2025-08-12 20:16:58,343 - INFO - Epoch [4000/5000], Batch [1/1], Loss: 0.4604 Avg Val Loss: 0.4608 Time: 0.04
2025-08-12 20:16:58,343 - INFO - Saving Checkpoint 3999
2025-08-12 20:16:58,395 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_3999.pt
2025-08-12 20:17:02,405 - INFO - Epoch [4100/5000], Batch [1/1], Loss: 0.4672 Avg Val Loss: 0.4604 Time: 0.04
2025-08-12 20:17:02,406 - INFO - Saving Checkpoint 4099
2025-08-12 20:17:02,454 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4099.pt
2025-08-12 20:17:06,410 - INFO - Epoch [4200/5000], Batch [1/1], Loss: 0.4590 Avg Val Loss: 0.4604 Time: 0.04
2025-08-12 20:17:06,411 - INFO - Saving Checkpoint 4199
2025-08-12 20:17:06,462 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4199.pt
2025-08-12 20:17:10,431 - INFO - Epoch [4300/5000], Batch [1/1], Loss: 0.4638 Avg Val Loss: 0.4604 Time: 0.04
2025-08-12 20:17:10,431 - INFO - Saving Checkpoint 4299
2025-08-12 20:17:10,480 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4299.pt
2025-08-12 20:17:14,476 - INFO - Epoch [4400/5000], Batch [1/1], Loss: 0.4815 Avg Val Loss: 0.4608 Time: 0.04
2025-08-12 20:17:14,476 - INFO - Saving Checkpoint 4399
2025-08-12 20:17:14,527 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4399.pt
2025-08-12 20:17:18,527 - INFO - Epoch [4500/5000], Batch [1/1], Loss: 0.4667 Avg Val Loss: 0.4603 Time: 0.04
2025-08-12 20:17:18,527 - INFO - Saving Checkpoint 4499
2025-08-12 20:17:18,574 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4499.pt
2025-08-12 20:17:22,579 - INFO - Epoch [4600/5000], Batch [1/1], Loss: 0.4664 Avg Val Loss: 0.4601 Time: 0.04
2025-08-12 20:17:22,580 - INFO - Saving Checkpoint 4599
2025-08-12 20:17:22,628 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4599.pt
2025-08-12 20:17:26,584 - INFO - Epoch [4700/5000], Batch [1/1], Loss: 0.4692 Avg Val Loss: 0.4608 Time: 0.04
2025-08-12 20:17:26,584 - INFO - Saving Checkpoint 4699
2025-08-12 20:17:26,634 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4699.pt
2025-08-12 20:17:30,632 - INFO - Epoch [4800/5000], Batch [1/1], Loss: 0.4688 Avg Val Loss: 0.4606 Time: 0.05
2025-08-12 20:17:30,632 - INFO - Saving Checkpoint 4799
2025-08-12 20:17:30,691 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4799.pt
2025-08-12 20:17:34,687 - INFO - Epoch [4900/5000], Batch [1/1], Loss: 0.4619 Avg Val Loss: 0.4601 Time: 0.04
2025-08-12 20:17:34,688 - INFO - Saving Checkpoint 4899
2025-08-12 20:17:34,738 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4899.pt
2025-08-12 20:17:38,747 - INFO - Epoch [5000/5000], Batch [1/1], Loss: 0.4684 Avg Val Loss: 0.4601 Time: 0.04
2025-08-12 20:17:38,747 - INFO - Saving Checkpoint 4999
2025-08-12 20:17:38,798 - INFO - Checkpoint saved to ./temp/single_stage/model_epoch_4999.pt
2025-08-12 20:17:38,798 - INFO - Training complete!
Plot Loss Curve#
To assess that the model is learning we plot both a training and validation loss curve.
Note. usually a validation is supposed to be another dataset. In this simple example we’re using the same data which typically is not usually the intent. Typically we want a model to generalize, meaning provide useful outputs on data it has not seen before. But in just this set of tutorials we are specifically seeking to overfit or memorize so we can clearly assess the effects of our reinforcement learning algorithms.
In the plot below the validation curve is lower than the training loss because it is making next token predictions without dropout. Usually it would be the opposite.
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(losses, label="Training Loss")
ax.plot(val_losses, label="Validation Loss")
ax.set_title("Training and Validation Loss Curve")
ax.set_xlabel("Epoch")
ax.set_ylabel("Loss")
ax.legend()
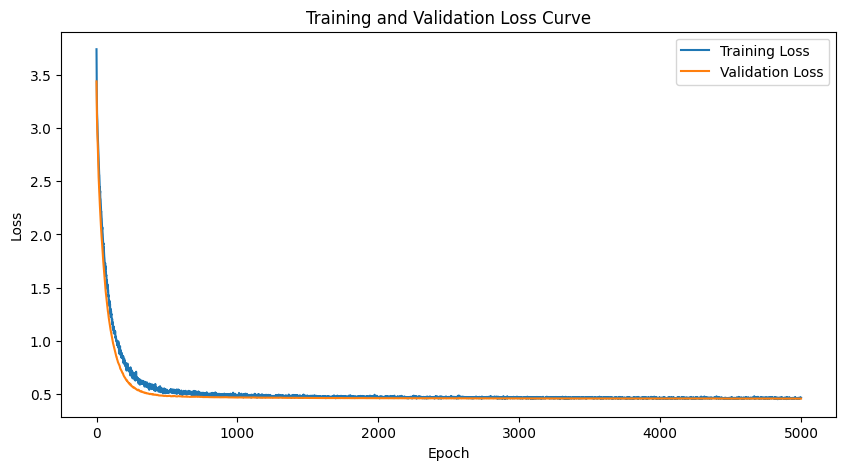
and zooming in we can
fig, axes = plt.subplots(2, 1, figsize=(10, 5))
for i in range(2):
axes[i].plot(losses, label="Training Loss")
axes[i].plot(val_losses, label="Validation Loss")
if i == 0:
axes[i].set_title("Training and Validation Loss Curve")
axes[i].set_xlabel("Epoch")
axes[i].set_ylabel("Loss")
axes[i].legend()
if i == 1:
axes[i].set_ylim(0, 1)
plt.show()
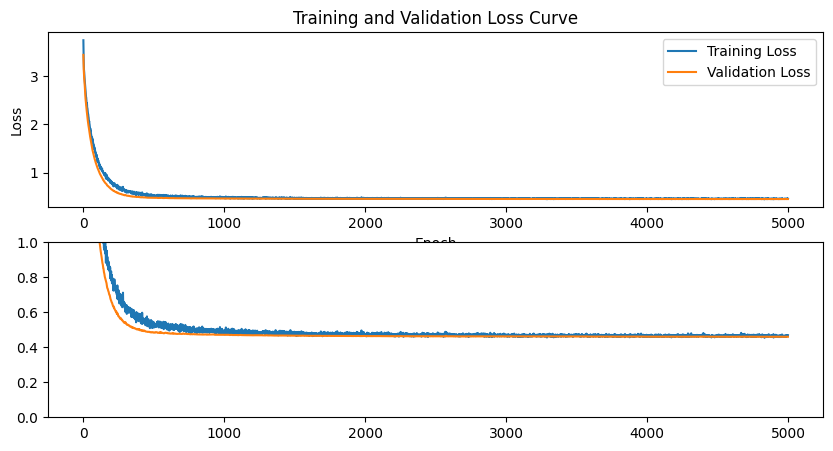
Final Sampling#
With our trained model we can now sample the completion. For the first one we start with a mostly complete sentence and see if the model can complete the word donuts, which it does.
prompt = "ravin likes don"
final_output = model.sample(tokenizer, prompt, max_completion_len=20, device=device, temperature=1)
final_output.text
'ravin likes donutsE'
We can then try a completion for Ravin and same without suggesting the actual food. As expected Ravin likes unhealthy food, and Sam by comparisos is prefers healthier salads.x
prompt = "ravin likes "
final_output = model.sample(tokenizer, prompt, max_completion_len=20, device=device, temperature=1)
final_output.text
'ravin likes sodaE'
# ax = sns.heatmap(final_output.completion_logits.cpu().T)
prompt = "sam likes "
sam_output = model.sample(tokenizer, prompt, device=device)
sam_output.text
'sam likes saladE'
We can also see the probability of next token predictions at any state.
temperature = 1
prompt = "ravin likes "
final_output = model.sample(tokenizer, prompt, max_completion_len=20, device=device, temperature=temperature)
print(final_output.text)
predictions = top_k_predictions(model, tokenizer, prompt, device, k=20, temperature=temperature)
for pred in predictions:
print(f"Token: '{pred['token']}', Probability: {pred['probability']:.2%}")
ravin likes saladE
Token: 's', Probability: 22.33%
Token: 'p', Probability: 13.06%
Token: 'a', Probability: 12.47%
Token: 'l', Probability: 12.23%
Token: 'd', Probability: 11.86%
Token: 'c', Probability: 11.56%
Token: 'i', Probability: 11.47%
Token: 'w', Probability: 0.40%
Token: 'o', Probability: 0.30%
Token: 'v', Probability: 0.28%
Token: 'f', Probability: 0.26%
Token: 'q', Probability: 0.26%
Token: 'x', Probability: 0.26%
Token: 'j', Probability: 0.26%
Token: 'b', Probability: 0.26%
Token: 'y', Probability: 0.26%
Token: 'S', Probability: 0.26%
Token: 'g', Probability: 0.26%
Token: 'P', Probability: 0.26%
Token: 'E', Probability: 0.25%
model.config
{'vocab_size': 30,
'd_model': 16,
'nhead': 4,
'num_decoder_layers': 6,
'dim_feedforward': 256,
'dropout': 0.1,
'context_length': 20,
'pad_id': 0}
model = pretrain.load_checkpoint("temp/single_stage/model_epoch_799.pt", device="mps")
model = pretrain.load_checkpoint("temp/single_stage/model_epoch_2999.pt", device="mps")
top_k_predictions(model, tokenizer, prompt, device, k=20, temperature=temperature)
[{'token': 's', 'probability': 0.2506028413772583},
{'token': 'a', 'probability': 0.1256905496120453},
{'token': 'd', 'probability': 0.12119297683238983},
{'token': 'p', 'probability': 0.1183789074420929},
{'token': 'l', 'probability': 0.115565724670887},
{'token': 'i', 'probability': 0.11067729443311691},
{'token': 'c', 'probability': 0.10604850947856903},
{'token': 'o', 'probability': 0.003219934180378914},
{'token': 'P', 'probability': 0.0029442324303090572},
{'token': 'f', 'probability': 0.002925768494606018},
{'token': 'b', 'probability': 0.0028436724096536636},
{'token': 'x', 'probability': 0.0028291719499975443},
{'token': 'h', 'probability': 0.0028145054820924997},
{'token': 'q', 'probability': 0.002813968574628234},
{'token': 'j', 'probability': 0.0027495003305375576},
{'token': 'm', 'probability': 0.0027393661439418793},
{'token': 'S', 'probability': 0.002725489903241396},
{'token': 'y', 'probability': 0.0027121908497065306},
{'token': 'g', 'probability': 0.0026499698869884014},
{'token': 'E', 'probability': 0.002354186726734042}]
And lastly we can get sample many times and see the generations. Our model is not perfect, but for our learning purposes this is exactly what we want. In future steps well see how RL changes this models behavior, both for the better when implemented well, and how it hurts performance when implemented poorly.
for _ in range(40):
final_output = model.sample(tokenizer, prompt, max_completion_len=20, device=device, temperature=temperature)
print(final_output.text)
ravin likes pSvettuceE
ravin likes sodaE
ravin likes pizzaE
ravin likes applesE
ravin likes ice creamE
ravin likes ttuceE
ravin likes donutsE
ravin likes sodaE
ravin likes pizzadonhesE
ravin likes pizzPE
ravin likes lettuceE
ravin likes ice creamE
ravin likes applesE
ravin likes sodaE
ravin likes pizzaE
ravin likes applesE
ravin likes saladE
ravin likes ice crokiesE
ravin likes sodaE
ravin likes apmE
ravin likes pizzajfE
ravin likes lettuceE
ravin likes ice creamdonutsE
ravin likes ice creamE
ravin likes ice creamE
ravin likes dokicresE
ravin likes lettuceE
ravin likes saladE
ravin likes cookiesE
ravin likes sodaE
ravin likes iSttuceE
ravin likes ice crdonutsE
ravin likes pizzaE
ravin likes lettuceE
ravin likes cookiesE
ravin likes applesE
ravin likes cookiesE
ravin likes donutsE
ravin likes ice cotsE
ravin likes pizzaE
References#
See pretraining guide in guidebook
Suggested Prompts#
How does the LLM trained here differ from large scale models? How is it similar?
How will the design choices with this LLM make RL and post training simpler?