
Audio Tokenization: An Overview#
TL;DR
Audio tokenization converts continuous audio signals into discrete, manageable units for machine learning and signal processing.
It’s crucial for tasks like:
speech recognition
music analysis
audio generation
cross-modal alignment.
Two main approaches:
Acoustic Tokens (focus on sound patterns).
Semantic tokens (emphasis on meaning).
Key methods include:
Future directions involve:
Improving robustness
Multimodal integration
Computational efficiency
Addressing privacy concerns.
Why Audio Tokenization is Important#
Audio tokenization bridges the gap between continuous audio signals and discrete computational processes. Unlike text or images, which are inherently discrete, audio exists as a continuous waveform, presenting unique challenges for digital processing and machine learning applications. This is why we usually convert audio into Hard Tokens: Processing audio as a continuous signal is computationally expensive and less efficient than processing it as discrete tokens.
In machine learning, Tokenization breaks down audio into smaller units called tokens, each assigned a numerical index. These tokens are then fed into the model (token encoding) and can be retrieved later (token decoding).
Fig. 59 Audio tokenization process simplified.#
In the context of audio, tokenization offers several advantages:
Enables efficient compression and analysis of audio data.
Compresses high-dimensional audio signals into compact representations.
Identifies and preserves significant audio elements. (e.g., phonemes in speech recognition)
Facilitates alignment between audio and other modalities (e.g., text, video).
By transforming continuous audio into discrete, manageable units, audio tokenization opens up numerous possibilities in audio processing, analysis, and generation across various fields.
Audio Tokens vs. Audio Features#
Since we’ve already covered audio features, let’s clarify the distinction between audio features and audio tokens:
Audio Features: These are numerical representations of various characteristics of the audio signal. Features like MFCCs, spectral centroid, or chroma are continuous values that describe different aspects of the sound. They are typically used directly in machine learning models.
Audio Tokens: These are discrete, symbolic representations of audio segments. Tokenization involves converting the continuous audio signal into a sequence of discrete elements, similar to how text is tokenized into words or subwords.
Important
Audio feature extraction is often a crucial step in the process of audio tokenization, particularly in methods like Vector Quantization (VQ). In a VQ-based system:
Features (e.g., MFCCs) are extracted from short segments of audio.
These feature vectors are then mapped to the nearest centroid in a codebook.
Each centroid is assigned a unique token or index.
The audio is thus represented as a sequence of these tokens.
This process allows for efficient compression and representation of audio, enabling applications like speech synthesis, audio compression, and advanced audio generation models.
Applications and challenges of Audio Tokenization:#
Audio tokenization serves as the foundation for a wide range of applications in audio processing, analysis, and generation. Its versatility spans across various domains, enabling innovative solutions to complex audio-related tasks. Here are some key applications:
Speech Processing:
Speech Recognition: Converting spoken language into text (e.g., Google Speech-to-Text).
Speaker Diarization: Identifying and separating speakers in a conversation (e.g., Pyannote).
Emotion Recognition: Detecting emotional states from speech (e.g., OpenSMILE).
Text-To-Speech: Generating realistic speech from text (e.g., Bark by Suno-AI).
Speech-to-Speech Translation: Translating speech between languages while preserving voice characteristics (e.g., OpenVoice by MyShell AI).
Music and Audio Generation:
Music Generation: Creating original music compositions (e.g., Magenta by Google).
Sound Effect Synthesis: Producing realistic sound effects for various applications from text and/or audio (e.g., AudioLDM).
Audio Enhancement and Restoration:
Noise Reduction and Dereverberation: Improving audio quality by removing unwanted noise and reverb (e.g., Resemble Enhance by Resemble AI).
Audio Upscaling: Enhancing the quality of low-fidelity audio (e.g., AudioSR).
Audio Classification and Analysis:
Genre Classification: Identifying music genres automatically (e.g., GTZAN Dataset and FMA).
Environmental Sound Recognition: Classifying various environmental sounds (e.g., ESC-50 Dataset).
Assistive Technologies:
Real-time Transcription: Providing text transcriptions for the hearing impaired (e.g., Google Live Transcribe).
The Challenges#
Audio tokenization faces several challenges, stemming from the complexity and variability of audio signals. These challenges are further compounded by the diverse nature of audio content, spanning speech, music, environmental sounds, and more. Here are some common challenges across different audio domains:
Category |
Common Challenges Across Audio Domains |
Specific Challenges in Speech Processing |
Specific Challenges in Music Processing |
|---|---|---|---|
Content Preservation |
Balancing information retention and compression |
Maintaining linguistic information and prosody |
Preserving musical structure, melody, and harmony |
Environmental Factors |
Separating signal from noise and artifacts |
Handling background noise, reverberation, and channel effects |
Dealing with mixing, production effects, and recording quality |
Temporal Content |
Encoding time-dependent information and long-term dependencies |
Representing speech rate, rhythm, and timing |
Capturing tempo, rhythmic patterns, and time signatures |
Spectral Content |
Efficiently encoding frequency information across different scales |
Preserving formants, pitch, and phonetic details |
Representing harmonic structure and spectral envelopes |
High Dimensionality |
Reducing data while preserving essential features and nuances |
Dealing with the richness of speech signals across speakers |
Handling complex polyphonic content and instrument interactions |
Variability |
Handling diverse audio inputs and generalization across domains |
Addressing speaker, accent, and language variations |
Dealing with musical style, genre, and cultural variations |
Continuity |
Ensuring coherent sequences of tokens |
Maintaining smooth transitions between speech segments |
Preserving musical phrasing and continuity |
Context Dependency |
Encoding both local and global dependencies in the audio |
Capturing co-articulation effects and context-dependent pronunciations |
Representing musical context and thematic development |
Implications for Tokenization and Transformer Models:#
The challenges in audio tokenization have direct implications for the design of tokenization methods and their integration with transformer models. Some key considerations include:
Adaptable Architecture: Models must be flexible enough to handle various audio domains and challenges.
Context-aware Tokenization: Tokens should consider both local and global audio context.
Low Delay Tokenization: Enabling low-latency tokenization for streaming applications. For reference, speakers find speech difficult when they hear themselves with > 25 ms delay.
Robust Representation: Tokenization should be resilient to noise and variations in audio quality.
Data Efficiency: Developing tokenization methods that perform well with limited training data.
Approaches to Audio Tokenization#
Current speech LMs utilize two primary audio tokenization methods: Acoustic Tokens, which focus on sound patterns, and Semantic Tokens, which emphasize meaning. However, it’s important to note that these categories are not mutually exclusive, and some methods may capture both acoustic and semantic properties to varying degrees.
Comparison of Acoustic and semantic Tokens#
Aspect |
Acoustic Tokens |
Semantic Tokens |
|---|---|---|
Focus |
Low-level acoustic properties |
High-level semantic information |
Objective |
Efficient compression and reconstruction |
Capturing meaningful audio units |
Training Approach |
Often unsupervised or self-supervised |
Typically self-supervised on large datasets |
Interpretability |
Generally less interpretable |
Can be more interpretable (e.g., phoneme-like units) |
Downstream Tasks |
Better for generation and reconstruction |
Better for classification and understanding tasks |
Cross-modal Alignment |
Less suitable |
More suitable for alignment with text or other modalities |
Compression Efficiency |
Usually higher |
Can be lower, as semantic information is prioritized |
Robustness to Noise |
Often more sensitive to acoustic variations |
Can be more robust to minor acoustic changes |
Language Dependency |
Generally language-independent |
May capture language-specific features |
Acoustic Tokens#
Acoustic tokens focus on representing the physical properties of the audio signal, capturing details of the audio waveform. These tokens are designed to encode low-level acoustic features such as pitch, loudness, and timbre. While often created through neural compression-based methods or codecs, they can also be generated using traditional signal processing techniques.
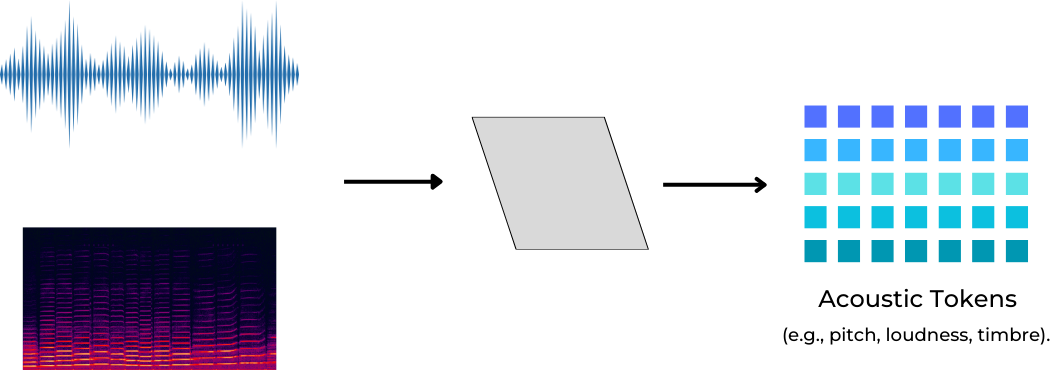
Fig. 60 Acoustic Tokenization works by transforming audio waveforms and spectral features into discrete acoustic tokens representing low-level sound characteristics such as pitch, loudness, and timbre.#
Common acoustic tokenization methods include:
Neural Compression-based Methods#
Vector Quantization (VQ): Vector Quantization (VQ) is a classic technique from signal processing that forms the basis of cutting-edge models like VQ-VAE and SoundStream (Google Research).
VQ works by dividing a large set of points (vectors) into groups having approximately the same number of points closest to them. Each group is represented by its centroid point, like a spokesperson for that group. When a new point is encountered, it is assigned to the group whose centroid is closest to it. This way, the continuous audio signal is converted into a sequence of discrete tokens. The VQ process typically involves two main steps:
Feature Extraction:
Raw audio is converted into a sequence of feature vectors.
This typically involves:
Dividing audio into short segments.
Transforming each segment into the frequency domain (e.g., using Fast Fourier Transform).
Computing relevant features (e.g., MFCCs, spectral properties).
Vector Quantization:
Uses a codebook, which is a collection of representative vectors (codewords).
Each input feature vector is assigned to the nearest codeword in the codebook.
The index of the assigned codeword in the codebook becomes a discrete token.
Benefits: VQ compresses complex audio features and enables the use of discrete algorithms on continuous audio data, facilitating efficient processing and representation.
Downsides: VQ inherently loses some information during quantization and may introduce discontinuities, while its effectiveness is limited by the quality of the codebook and its ability to generalize across different audio types.
Tutorial: For a hands-on tutorial on VQ, check out this section in the Audio Tokenization Tutorial.
Example: VQ-Wav2Vec for speech recognition.
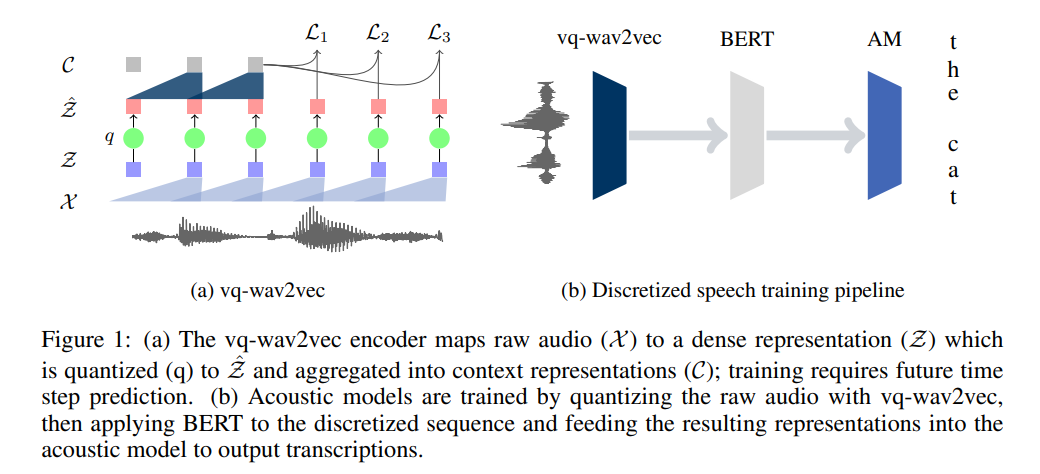
Fig. 61 VQ-Wav2Vec process. Raw audio → Feature vectors → Discrete tokens via codebook mapping.#
Neural Audio Codecs:
Utilize deep learning to compress audio into discrete tokens.
These discrete tokens are typically produced by a vector quantization layer or a similar discretization mechanism within the neural network.
Offer high compression ratios while maintaining audio quality.
Their main advantages include superior compression ratios, adaptability to various audio types, and potential for continuous improvement through machine learning advancements. However, they come with downsides such as higher computational complexity, potential for unique artifacts, and dependency on training data, which may limit generalization across all audio scenarios.
Examples:
EnCodec (Meta AI): Efficient neural audio codec for high-quality compression.
SoundStream (Google Research): End-to-end neural audio codec with adaptive bit-rate.
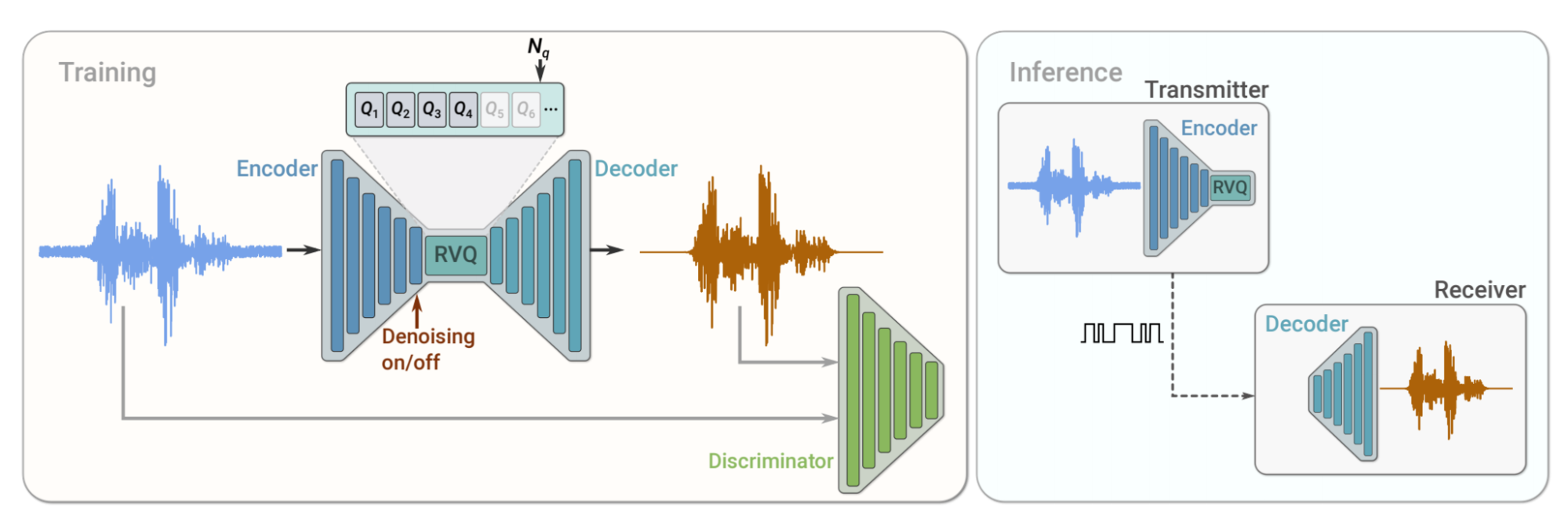
Fig. 62 Snippet from the SoundStream paper illustrating the architecture of the neural audio codec.#
SoundStream tokenization process:
Encoding: Transform input audio into latent representation using CNNs.
Vector Quantization: Map latent representations to a fixed codebook of vectors.
Residual Vector Quantization: Apply multiple quantization stages to capture different detail levels.
Decoding: Reconstruct audio signal from quantized tokens using a neural network decoder.
Adversarial Training: Employ a discriminator to improve reconstructed audio quality.
RVQGAN (Improved Residual Vector Quantized Generative Adversarial Network):
High-fidelity audio compression technique.
Combines VQ with adversarial training for improved quality.
Examples: TSAC, Descript Audio Codec
Traditional Signal Processing Methods#
Mel-Frequency Cepstral Coefficients (MFCCs):
Widely used in speech and music processing.
Represents the short-term power spectrum of sound, mimicking human auditory perception.
For a deeper understanding, we wrote a whole section on MFCCs.
Linear Predictive Coding (LPC):
Models the human vocal tract as a linear filter.
Efficient for representing speech signals.
Widely used in speech coding, compression, and synthesis.
Short-time Fourier Transform (STFT) based methods:
Provides time-frequency representation of the signal.
Useful for spectral analysis, modification, and feature extraction.
Forms the basis for many advanced audio processing techniques.
Bridging Acoustic and Semantic Tokenization#
HuBERT (Hidden-Unit BERT):
Primarily an acoustic tokenizer that can bridge towards semantic representation.
Generates discrete labels for speech using an iterative hidden state clustering method.
While starting with acoustic features, its self-supervised learning can lead to the emergence of some semantic-like representations in higher layers.
Useful for tasks like speech recognition and speaker identification.
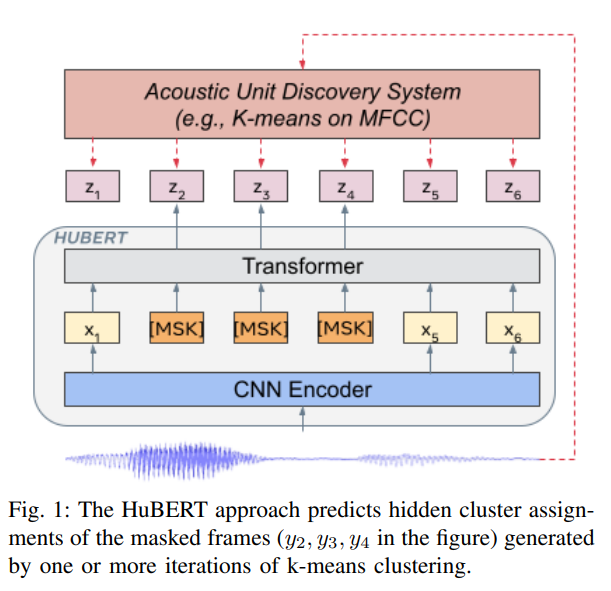
Fig. 63 Snippet from the HuBERT paper illustrating the architecture of the model.#
The HuBERT approach for audio tokenization works as follows:
CNN Encoder: Processes the input audio waveform to extract feature representations.
Masking: Some feature representations are masked (denoted by
[MSK]) to create a pretext task.Transformer: Processes the features, including masked ones, to understand context and relationships.
Acoustic Unit Discovery System: Uses techniques like K-means clustering on MFCC features to generate discrete cluster assignments (
z1, z2, ..., z6).Audio Tokens: The cluster assignments represent the audio tokens, capturing essential phonetic or acoustic units.
Token Prediction: The model is trained to predict hidden cluster assignments of masked frames based on context.
These acoustic tokenization methods offer various approaches to represent audio signals in discrete, manageable units while preserving essential acoustic information. The choice of method often depends on the specific application, computational resources, and desired trade-offs between compression efficiency and audio quality.
Semantic tokens#
Semantic tokens aim to capture higher-level, meaningful units in the audio. These tokens represent linguistic or contextual information rather than just acoustic properties. While typically created through learned tokenization, some approaches use rule-based or knowledge-driven methods to extract semantic information.
Fig. 64 Semantic Tokenization works by transforming audio signals into discrete semantic tokens representing higher-level linguistic or contextual information.#
Some common semantic tokenization methods include:
Learned Tokenization Methods#
-
Self-supervised learning framework for speech, text, and vision.
Improves upon the original Data2Vec with more efficient training.
Excels in speech recognition tasks by learning contextualized speech representations from large amounts of unlabeled audio data.
-
Optimized for tasks like music search by humming and speech search via audio queries.
Learns to map audio directly to semantic token sequences.
Can capture high-level semantic information in audio without relying on intermediate phonetic representations.
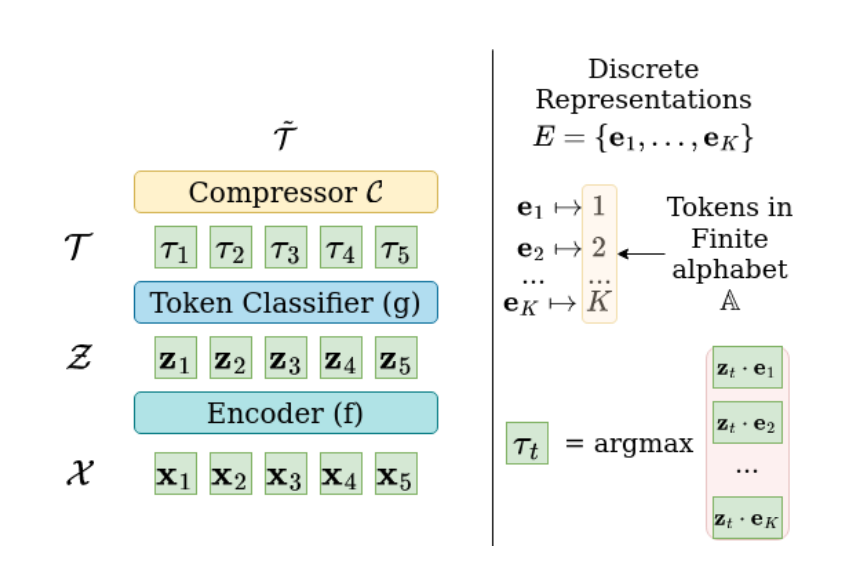
Fig. 65 Snippet from the Wav2tok paper illustrating the architecture of the model.#
wav2tok transforms audio into discrete tokens in three steps:
Encoder (f):
Converts audio features into a sequence of vector representations.
Uses a BiLSTM network to capture context in both directions.
Vector Quantizer (g):
Maps each vector to its closest match in a learned codebook.
Assigns a token based on the chosen codebook vector.
Compressor (C):
Removes repeated consecutive tokens.
Averages the corresponding representations for compressed tokens.
Rule-based or Knowledge-driven Methods#
Phoneme extraction using linguistic rules:
Uses phonetic and linguistic knowledge to segment speech into phonemes.
Can be combined with statistical methods for improved accuracy.
While phonemes are acoustic units, their extraction often relies on language-specific rules, bridging to semantic understanding.
Music transcription to MIDI:
Converts audio to symbolic music representation.
Uses signal processing and music theory rules.
The resulting MIDI representation captures semantic musical elements like notes, instruments, and timing.
Semantic tokenization methods aim to create representations that are closer to human understanding of audio content. These tokens can be particularly useful for tasks requiring high-level interpretation of audio, such as speech recognition, music information retrieval, and audio-based search engines.
Hybrid Approaches#
Many modern audio tokenization methods combine aspects of both acoustic and semantic tokenization, aiming to capture a more comprehensive representation of audio:
-
Combines semantic and acoustic tokens in a hierarchical fashion.
Uses semantic tokens for high-level structure and acoustic tokens for fine-grained details.
Enables generation of high-quality, coherent audio samples.
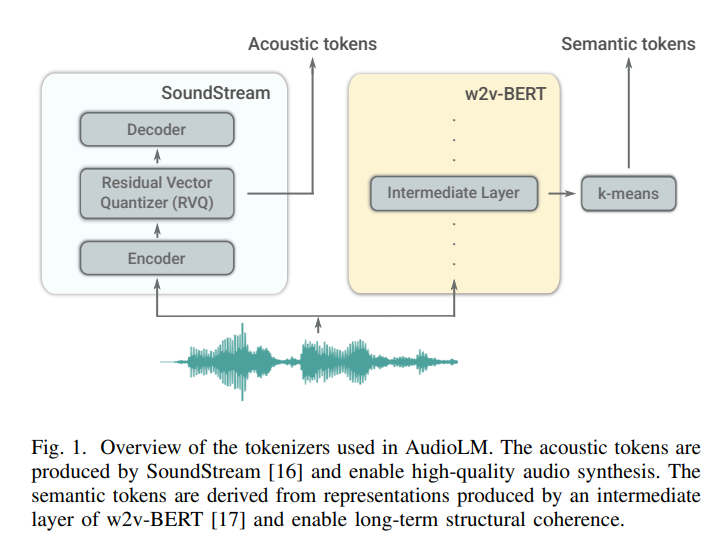
Fig. 66 Snippet from the AudioLM paper.#
-
Uses a hierarchical VQ-VAE to capture both low-level acoustic details and high-level musical structure.
Employs three levels of compression, each focusing on different aspects of music.
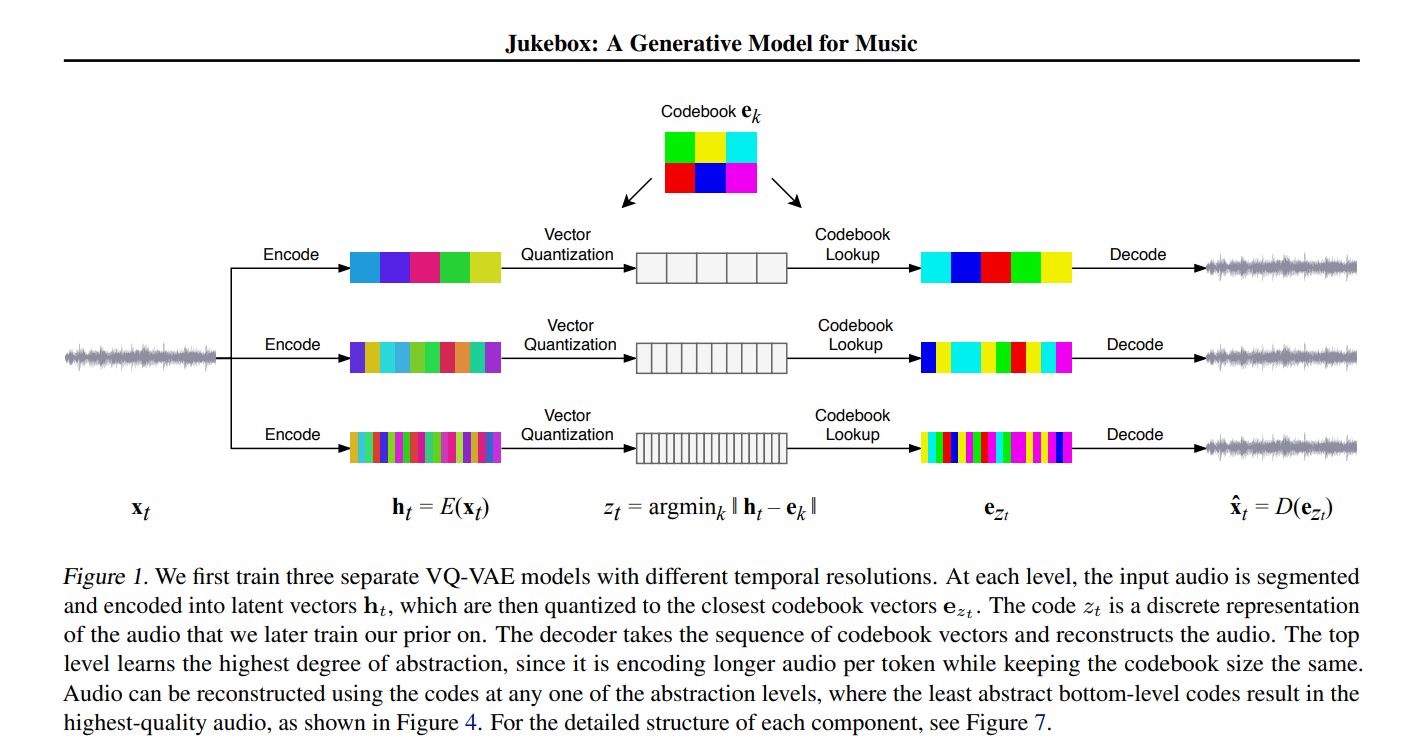
Fig. 67 Snippet from the Jukebox paper illustrating the hierarchical VQ-VAE architecture.#
COLA (Contrastive Learning of Audio Representations):
Combines contrastive learning with quantization to learn multi-scale audio tokens.
Focuses on learning representations that are invariant to data augmentations.
GSLM (Generative Spoken Language Model):
Uses both acoustic and semantic units to model speech in an unsupervised manner.
Aims to learn the structure of speech without relying on text transcriptions.
These hybrid approaches demonstrate the evolving landscape of audio tokenization, where methods increasingly seek to capture both the acoustic properties and semantic content of audio signals. This combination often leads to more versatile and powerful representations for various audio processing tasks.
Evaluation Metrics of Audio Tokenization#
Assessing audio tokenization methods involves various metrics, depending on the specific use case or application. Here are some key evaluation criteria for audio tokenization:
Quality of Tokenization
Reconstruction Accuracy: Measure how well the original audio can be reconstructed from tokens using Signal-to-Noise Ratio (SNR) or Mean Squared Error (MSE).
Perceptual Quality: Evaluate using human listening tests or automated metrics like PESQ or STOI.
Compression Efficiency
Compression Ratio: Compare original audio size to tokenized representation size.
Bitrate: Assess the transmission bitrate of tokenized audio versus original audio.
Representation Robustness
Noise Handling: Test performance with various types and levels of added noise.
Variability Management: Evaluate across different audio types, speakers, accents, and emotions.
Efficiency and Scalability
Computational Efficiency: Measure processing time, memory usage, and computational requirements.
Scalability: Assess performance with longer inputs or higher sample rates.
Token Characteristics
Stability: Ensure consistent tokens for similar audio segments.
Diversity: Verify distinct tokens for different audio segments.
Generalization Ability
Cross-Dataset Performance: Test on multiple datasets for broad applicability.
Adversarial Robustness: Evaluate against specially crafted inputs designed to challenge the system.
Comparative Analysis
Baseline Comparison: Benchmark against state-of-the-art methods.
Ablation Studies: Analyze the impact of individual components on overall performance.
Downstream Task Performance
Classification Accuracy: Using metrics like F1 score or accuracy.
Generation Quality: Assess the quality of generated audio samples. This can be subjective or objective using metrics like MOS (Mean Opinion Score).
Alignment Accuracy: Measure the alignment between audio and text or other modalities. For a deeper dive into evaluation metrics for Large Language Models, check out this guide.
Future Directions and Open Challenges#
Improving Robustness and Generalization:
Future research aims to enhance the robustness of audio tokenization methods, particularly in diverse and noisy environments.
This involves developing models that can generalize well across different languages, accents, and recording conditions.
Integration with Multimodal Systems:
Another direction is the integration of audio tokenization with multimodal systems that combine audio with text, video, and other sensory inputs.
This can improve the performance of applications like automatic transcription, video understanding, and human-computer interaction.
Efficiency and Scalability:
Addressing the computational efficiency and scalability of audio tokenization methods is crucial.
Optimizing models to run efficiently on various hardware, including consumer devices, is a significant challenge.
Security and Privacy:
Ensuring the security and privacy of tokenized audio data remains a concern.
Developing methods to securely process and store audio tokens while protecting user privacy is an ongoing challenge.
References#
Discrete Audio Representation as an Alternative to Mel-Spectrograms for Speaker and Speech Recognition: Explores how discrete audio tokens can effectively compete with mel-spectrograms in speech tasks while offering significant compression.
How Should We Extract Discrete Audio Tokens from Self-Supervised Models?: this study explores optimal methods for extracting semantic audio tokens from self-supervised learning models, focusing on preserving multiple aspects of audio (content, paralinguistic elements, speaker identity).
Encoder-Decoder: Features Extraction: A good explanation of the encoder-decoder architecture and feature extraction in audio processing.
AudioLM: a Language Modeling Approach to Audio Generation: The AudioLM paper detailing a hierarchical tokenization approach for audio generation.
SoundStream: An End-to-End Neural Audio Codec: Google Research’s blog post on SoundStream.
Self-Supervised Speech Representation Learning: A Review: Presents approaches for self-supervised speech representation learning and their applications beyond speech recognition.
Neural Discrete Representation Learning: The original paper on VQ-VAE, a key method for audio tokenization.
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units: The HuBERT paper.