
Inference Optimization#
TL;DR
When scaling LLM inference you end up at either a compute bound or memory bound.
Many AI advancements are moving to inference time methods, which is fueling research and advancement in this area. These include:
Multi-step reasoning models, such as o3 models
Agents
Long output generation
By understanding which bound you’ll encounter, you’ll be able to better utilize your hardware, save costs and time.
A number of strategies are used:
and more
The depth of knowledge you’ll need depends on:
The specifics of your application
The type of user you are (API, Open weights, Researcher)
If 2023 and 2024 were the years of training, 2025 is shaping up to be the year of inference. Between o3 models and agents, we’re finding a lot of power in prompting a model multiple times. Even if you just prompt the model once, inference speed is still a prime concern. If you are building an application, the speed of inference can be the difference between a viral product versus one that’s unusable. NotebookLM interactivity and GPT Voice mode are two such products where speed is a critical part of the user experience. And no matter what you do, cost is always a concern.
For all these reasons, inference is getting a great deal of mindshare from model and product developers. Along with model architecture, data, and evaluation performance, you should have a good understanding of inference as well.
How much do you need to know?#
Similar to the other guides in this guidebook, this largely depends on your use case and what kind of user you are. Here are the rough categories I use.
Considerations#
Use Case - The use case is by far the most important consideration. For example, are you processing single prompts or batches of prompts? Is there an expectation of a real-time response, etc.?
Model choice (and size) - Some use cases require larger models. If so, you’ll be using more compute and memory.
High vs Low Throughput - How many inference passes do you need? Tens, Hundreds, Hundreds of thousands?
First Token Latency - How quickly do you need the outputs to start, but not necessarily finish? This is important if users are expecting a real-time experience.
Total Processing Time - How quickly do you need outputs from start to finish?
Ability to Batch - Can many requests be run in parallel?
Variation in Inputs - Is anything common between all the prompts, for example, a shared system instruction?
Who’s implementing the inference?#
Are you implementing inference by yourself or are you relying on an expert to handle it for you? The categorization I use here are:
API User - You’re delegating most of the inference time concerns to the model provider. You still need to make some choices, though, and be aware what those are so you can turn them on if your use case would benefit.
Open Weights User - You’ll have more control over inference. You’re going to size models to your machine and you’ll have compute limitations. You’ll likely want to squeeze the most out of your hardware.
Researcher - You’re an expert, your inference time needs will depend on your research. It’s (relatively) easy to make a model 10% better by making it 10% more expensive to run. The real trick is getting more performance with fixed, or less, compute.
In the rest of this guide, I’ll point out which topics are relevant to which subsets.
The Basics#
Roofline plots and caching are two concepts that all folks building on top of LLMs should understand. Small choices can save an enormous amount of time and money.
Compute, Memory, and Associated Plots#
LLMs require a lot of compute, and often LLMs are run on specialized hardware such as GPUs and TPUs, also referred to as AI accelerators, which are quite expensive, and often in short supply.
A basic mistake is to spend lots of money getting the biggest one in the hope it works. A better strategy is understanding your **Compute Intensity** and **Memory Intensity**. The short intuition here is if your inference needs or model are relatively small, then your application won't run into any constraints. But once you start scaling things you'll either hit a compute or memory bandwidth limit.For example, think of a restaurant. If only a few customers are entering, the restaurant won’t reach any capacity limits. But once the restaurant gets busy, one of two things will happen: either your chefs will be overwhelmed preparing dishes at their stations (compute bound), or they’ll be overwhelmed fetching ingredients from the pantry or refrigerator (memory bandwidth bound).
To understand which, you’ll need to construct a roofline plot, or a similar variant such as this plot from Databricks.
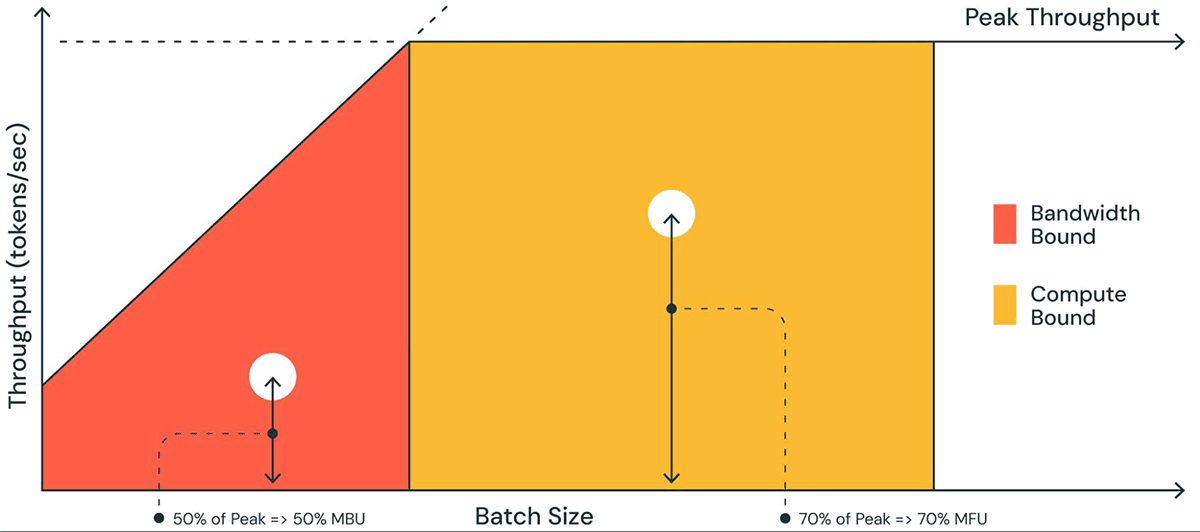
Fig. 47 A plot of compute and model bandwidth utilization from Databricks, showing how different input profiles can either be constrained or underutilized.#
One point of confusion is that numerous metrics now exist in this space, Memory Bandwidth Utilization, Model Flops Utilization, Operational intensity. While the general concept is the same, this often makes it difficult to compare metrics against different models and hardware.
API Users#
For API users, it’ll be tough to produce an exact roofline plot. You’ll lack details about the model, the serving hardware, or both. My suggestion is to create a roofline plot using (what you believe) is a similar open-source model. For instance, if using a large model like GPT-4, estimate compute and memory bounds using LLAMA3 405b.
Caching#
The next common strategy is caching. For example, during inference, (key, value) pairs can be cached leading to massive speedups. The GIFs in this Medium post highlight what is being cached quite well. There are multiple types of caching beyond KV caches. Many of them can be seen in the Hugging Face Transformers library. For API users, most cloud providers also provide caches. However, the names are different per provider. Google calls theirs a context cache, while Anthropic labels it prompt cache. But either way, with repetitive prompts you can get huge speedups and savings with smart caching.
The Advanced Stuff#
API users can stop reading here. Due to the fact that others are hosting models, you’ll have little control or knowledge of anything past this section. Open weights users or researchers can consider these strategies.
Quantization#
The easiest way to reduce memory and compute needs, is to make the individual model’s float values smaller. Quantization is one such strategy that is frequently used, reducing the precision of the model weights, often with little quality loss. For more details, read the quantization guide.
Speculative Decoding#
Have a fast model write for you, then have a big model check in parallel. That is speculative decoding. An animation in this Google Research blog post shows the inference and checking process visually.
The intuition I use is a grandparent, who writes slowly due to age, checking the work of a much younger but faster grandchild. The grandchild can put words on paper quickly, and the grandparent checks the child’s writing every couple of words.
A key point made in the Google blog post is that speculative decoding especially makes sense because the current hardware is memory bound. This leaves compute cycles free to run smaller models at the same time as the larger one. When picking an inference framework, check if speculative decoding is available if you need your inference speed to be fast. [llama.cpp now supports it](https://github.com/ggerganov/llama.cpp/pull/10455) but it seems at the time of writing not every framework does.Constrained Decoding#
LLMs can generate many things, but sometimes we know we want specific things. For example, if asked for the output of a math formula, it should output an integer. That can be enforced using constrained decoding. Here is one example from the Outlines library.
prompt = "<s>result of 9 + 9 = 18</s><s>result of 1 + 2 = "
answer = outlines.generate.format(model, int)(prompt)
print(answer)
# 3
By constraining the output, we can ensure the LLM just outputs what is needed, and nothing more, saving on inference costs from overly verbose examples.
For other situations like JSON outputs, the schema is known prior to generation. We don’t need the LLM to infer the schema itself since constrained decoding libraries can complete those values using existing knowledge, without needing the LLM.
References#
Survey Paper on Inference Optimization - A great overview of inference optimization techniques, with practical calculations assuming the accelerator used is an NVIDIA A6000.
Canonical Reference for Roofline Plots - A general overview of roofline models for any application, not just AI ones
Youtube overview on roofline analysis - A concise explainer video on roofline plots.
PALM Model Flops Utilization - Appendix B of the Palm Paper covers the model compute cost in great detail, and establishes Model Flops Utilization as one measure of model cost.
Baseten Guide to operational intensity - A great worked-through example of intensity and bound calculations using Llama 2 as a concrete example.
KV Cache Explanation - A detailed blog post on how KV caching saves computational cost in inference.
CUDA Guide for fast inference - A near bare metal explanation of compute optimization for GPU inference.
Pros and Cons of Constrained Decoding - A well-written blog post on constrained decoding, especially different types, with code and practical examples.
A short analogy on accelerators and memory#
For those relatively new to compute, the difference between CPUs, GPUs, and memory can be a bit confusing. Here’s a mental analogy I use to frame the basic concepts. Imagine a sandwich shop that is taking in hundreds of orders a day. You have a head chef that is managing a staff and making custom orders. The head chef is supported by a team of specialized prep staff that perform routine tasks, such as cutting vegetables and slicing bread.
CPUs are the head chef. They excel at a wide variety of sequential tasks, one after the other. They can handle branching tasks with ease, such as “if allergies then no peanuts”, however, they’re not great at repetitive tasks. A kitchen typically has one or two head chefs.
GPUs are the prep staff. They perform repetitive operations in parallel. These tasks are typically of a more narrow scope. There can be hundreds of prep staff, performing these tasks rapidly in parallel. Once the ingredients are prepped, they are delivered to the head chef who puts them together into the final meal. For both chefs, the easy versus hard tasks are analogous to compute intensity.
Finally, memory is the location of the ingredients. A small amount of ingredients can be stored on the counter within arms reach of the chefs. Perhaps some more can be stored near their work location, but not immediately on the counter. The rest are in the fridge which requires a walk, and if more are needed it has to be fetched from a warehouse with a truck. You can imagine that if a chef constantly has to walk back and forth from the large refrigerator to grab ingredients, their prep time will be slow. This is the same idea with caches, onboard memory like DRAM or VRAM, and loading weights from disk. The amount of things and where they need to come from are analogous to memory. The difficulty of getting the right things into the right place is analogous to memory intensity.
When I used to design restaurants and factories, substantial changes in workload/inputs resulted in redesigns of the factory. The same will hold true for your LLM application; the type of work will inform the right balance of compute and memory you will need.