
Image Tokenization#
TL;DR
Image tokenization is the process of transforming images into compressed, representative units called tokens.
In computer vision and AI, Image tokenization is essential for efficient
processing
scalability
cross-modal applications
There are two main types of image tokenization:
Hard tokens are discrete and represent distinct elements or regions of an image.
Soft tokens are continuous and allow for more flexible encoding of image information.
Popular image tokenization methods include:
Vision Transformers (ViT): Apply transformer architecture to vision tasks.
CLIP (Contrastive Language-Image Pretraining): Align images and text in a shared embedding space.
Recent advancements in image tokenization include:
SigLIP
PaLI-3
PaliGemma
LLaMA 3.2
What’s Image Tokenization?#
Image tokenization is a fundamental process in computer vision and AI, especially now with the recent advancements in Transformers and Diffusion models. It involves transforming images into compressed, representative units called tokens. These tokens exist in a latent space that is significantly smaller than the original image space, making them easier and more efficient to process. Think of it like translating a complex sentence into a few key words – you lose some detail, but capture the essence more efficiently.
Why Image Tokenization Matters#
Do we really need to tokenize images? Why not just work with raw pixels? Here are a few good reasons:
Efficiency: Processing raw pixels is computationally expensive. Tokenization compresses images, reducing the computational load and enabling the development of more scalable models.
Effectiveness: Tokens can be designed to capture high-level semantic information about an image, making them valuable for tasks like image generation and understanding.
Scalability: The compact nature of tokenized representations facilitates the development and training of larger, more powerful models.
Interpretability: Some tokenization methods can provide more interpretable representations of images, making it easier to understand how ML models are processing visual information.
Cross-modal applications: Image tokenization enables the integration of visual data with other modalities, such as text or audio. This is particularly important for developing multimodal AI systems that can understand and generate content across different types of media.
Types of Image Tokenization#
Image tokenization methods can be broadly categorized into two main types: hard tokens and soft tokens. Hard tokens are discrete, and Soft tokens are continuous.[1], [2]
Each approach has its own set of characteristics, advantages, and limitations. Here’s a closer look at each type to help you understand the differences and make an informed decision when choosing a tokenization method for your project.
Hard Tokens#
Hard tokens, also known as discrete tokens, are strictly defined, non-overlapping units that represent distinct elements or regions of an image. These tokens are typically created through methods such as:
Grid-based segmentation.#

Fig. 48 Grid based Image Segmentation.#
Grid-based segmentation is a straightforward yet effective method for dividing an image into uniform, fixed-size cells, each representing a token. This approach offers several advantages:
Simplifies processing by ensuring consistency across the image
Facilitates tasks requiring spatial relationship analysis
Provides a structured input format for certain deep learning models
Useful for applications like image classification and feature extraction
The uniform nature of grid-based segmentation makes it particularly valuable in scenarios where maintaining spatial relationships within the grid is crucial for analysis or model input.[3], [4]
Object Detection Techniques#
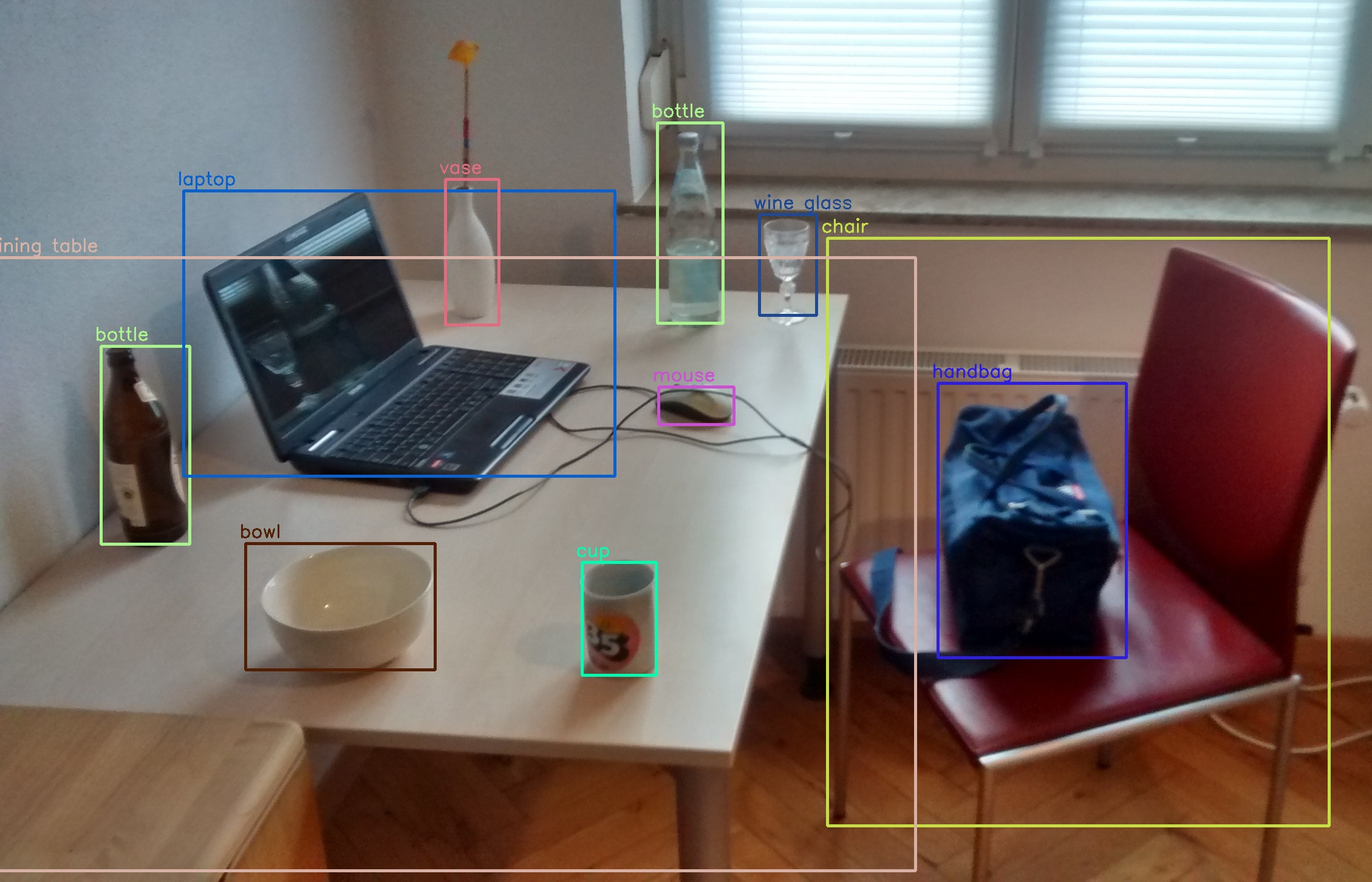
Fig. 49 Object Detection using YOLO (You Only Look Once) Algorithm. Source#
Object detection techniques identify and extract specific entities or regions of interest within an image, treating each as a separate token. Modern approaches rely heavily on deep learning architectures like YOLO (You Only Look Once) and Faster R-CNN, which have significantly improved accuracy and speed compared to traditional methods.[5], [6]
Key aspects of object detection include:
Bounding boxes to indicate object locations
Class labels for categorizing detected objects (e.g., car, person, animal)
Performance evaluation using metrics like Average Precision (AP)[5]
Applications in autonomous vehicles, surveillance, and robotics [7], [8]
These techniques enable systems to recognize and localize multiple objects simultaneously, providing crucial information for tasks such as scene understanding and object tracking.
Advantages:
Clear and interpretable representation of image elements
Efficient storage and processing due to discrete nature
Suitable for tasks requiring explicit object or region identification
Limitations:
Can lose fine-grained details or subtle features
May struggle with ambiguous boundaries or complex scenes
Limited flexibility in representing continuous or gradual changes in images
Soft Tokens#

Fig. 50 CNN Image Segmentation into soft tokens.#
Soft tokens, also referred to as continuous or dense tokens, are representations that allow for more flexible and nuanced encoding of image information. These tokens often use continuous values or probability distributions to represent features across the image.[2]
Soft tokens are commonly generated through methods like:
Convolutional Neural Networks (CNNs): Extract features from images using convolutional layers, producing continuous feature maps that can be interpreted as soft tokens.
Self-attention mechanisms: Capture long-range dependencies and relationships between image regions, enabling the creation of soft token representations.
Diffusion models: Propagate information across the image in a continuous manner, generating soft tokens that reflect the underlying structure of the image.
Autoencoders: Learn compact, continuous representations of images through unsupervised learning, producing soft tokens that capture essential image features.
For example, Variational Autoencoders (VAEs) can be used to generate soft tokens that represent images in a continuous latent space. This process is illustrated in the figure below:
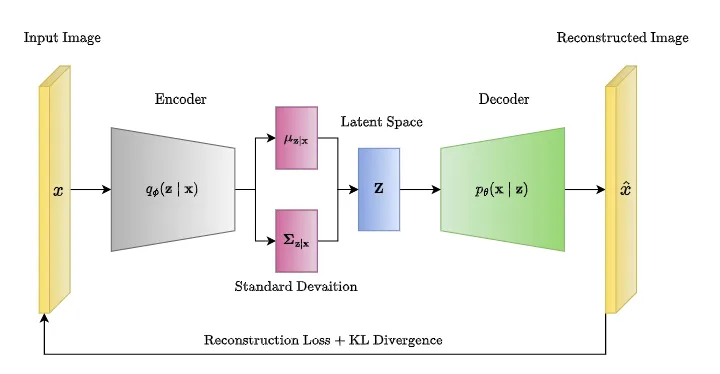
Fig. 51 Variational Autoencoder (VAE) Architecture for Image Tokenization. source#
VAEs learn to encode images into a continuous latent space, where each point represents a potential image token. This continuous representation allows for smooth interpolation between tokens and the generation of new images by sampling from the latent space.
Advantages of soft tokens:
Can capture fine-grained details and subtle variations in images
More adaptable to complex scenes and ambiguous boundaries
Better at representing continuous features like textures or gradients
Limitations:
Can be more computationally intensive to process
May be less interpretable compared to hard tokens
Potentially more challenging to integrate with discrete reasoning systems
Hard vs. Soft Tokens Comparison#
The choice between hard and soft tokens depends on the specific requirements of your application. Many modern computer vision systems use a combination of both approaches to leverage their respective strengths and mitigate their limitations. Here’s a comparison of their characteristics, performance, and use case scenarios:
Characteristics#
Aspect |
Hard Tokens |
Soft Tokens |
|---|---|---|
Nature |
Discrete, non-overlapping |
Continuous, potentially overlapping |
Representation |
Distinct objects or regions |
Flexible feature distributions |
Interpretability |
High |
Moderate to Low |
Detail Preservation |
May lose fine details |
Preserves subtle features |
Computational Efficiency |
Generally more efficient |
Can be more intensive |
Boundary Handling |
Struggles with ambiguous boundaries |
Better with complex boundaries |
Scalability |
Highly scalable |
Scalable, but may require more resources |
Applications#
Performance Comparisons |
Hard Tokens |
Soft Tokens |
|---|---|---|
Object Detection |
Excellent |
Good |
Semantic Segmentation |
Very Good |
Excellent |
Texture Analysis |
Fair |
Excellent |
Fine-grained Classification |
Good |
Excellent |
Use Case Scenarios#
Use Case Scenarios |
Hard Tokens |
Soft Tokens |
|---|---|---|
Medical Imaging |
Tumor detection, organ segmentation |
Tissue analysis, subtle anomaly detection |
Autonomous Driving |
Object detection (cars, pedestrians) |
Road surface analysis, environmental mapping |
Facial Recognition |
Identifying facial landmarks |
Capturing subtle expressions, age estimation |
Satellite Imagery |
Building and road detection |
Land use classification, vegetation analysis |
Popular Image Tokenization Methods#
As the field of computer vision advances, several image tokenization methods have emerged, each with its own strengths and applications. Let’s explore some of the most popular and effective approaches.
Vision Transformers (ViT)#
Vision Transformers (ViT) introduced a novel way to approach image understanding by applying the transformer architecture (usually used for Natural Language Processing) to vision tasks. Unlike the conventional Convolutional Neural Networks (CNNs) that rely on convolutional layers to capture local image patterns, ViTs treat an image as a sequence of smaller patches, similar to how transformers process sequences of words in text.
How Vision Transformers Work#
Here’s a high-level overview of how Vision Transformers work
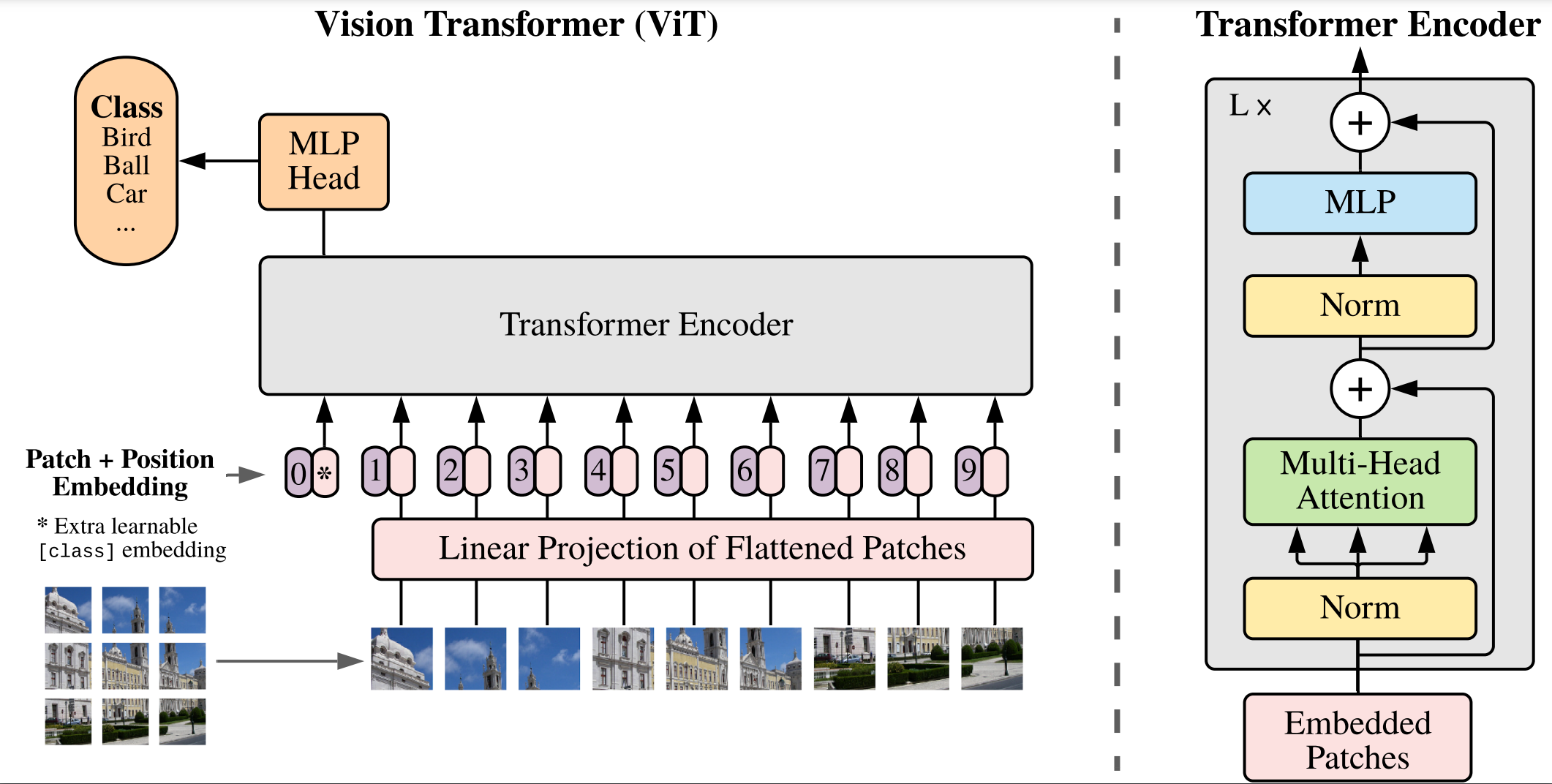
Image Patch Tokenization: The input image is divided into fixed-size patches (e.g., 16x16 pixels). Each patch is treated as a “token,”. These image patches are flattened and projected into a fixed-size vector using a linear embedding layer, creating a sequence of patch embeddings.
Positional Encoding: Since transformers are designed to process sequences, they don’t inherently understand spatial relationships between tokens (image patches). To preserve the spatial structure of the image, positional encodings are added to the patch embeddings. This helps the model understand where each patch is located in the original image.
Transformer Architecture: The sequence of patch embeddings is fed into a standard transformer encoder. This consists of multiple layers of self-attention mechanisms and feed-forward neural networks, allowing the model to capture long-range dependencies between different patches. Self-attention enables the model to focus on relevant parts of the image by learning relationships between all patches, regardless of their distance in the image.
Classification Token and Output: A special token called the CLS token (short for classification token) is appended to the sequence of patches. After processing the entire sequence through the transformer layers, the output of this token is used to perform classification tasks (e.g., identifying objects or scenes in the image).
Advantages of Vision Transformers#
Scalability: ViTs can scale well with large datasets. Their performance improves significantly as the dataset size increases, making them competitive with CNNs on tasks like image classification and object detection.
Global Understanding: Unlike CNNs, which focus on local patterns, ViTs can model global relationships between image patches early on, leading to improved performance on complex visual tasks.
ViTs have demonstrated that transformers can excel in vision tasks, offering a flexible and scalable alternative to traditional CNN architectures, especially when large-scale datasets like ImageNet or COCO are available for training.
Drawbacks of Vision Transformers#
Computational Complexity: Training ViTs can be computationally expensive, especially for large-scale models with many parameters. This can limit their practicality for resource-constrained environments.
Data Efficiency: ViTs may require large amounts of data to achieve optimal performance, which can be a limitation in scenarios where labeled data is scarce.
Fine-grained Details: While ViTs perform well on high-level tasks like image classification, they may struggle with capturing fine-grained details in images compared to CNNs.
CLIP (Contrastive Language-Image Pretraining)#
CLIP (Contrastive Language–Image Pretraining), by OpenAI, represents a major advancement in multimodal learning by aligning images and text in a shared embedding space. CLIP enables models to understand and reason about images and text together, leading to zero-shot capabilities. This is achieved through a dual-encoder architecture that processes images and text simultaneously, learning to associate them in a shared embedding space.
How CLIP Works#
Here’s an overview of how CLIP works:
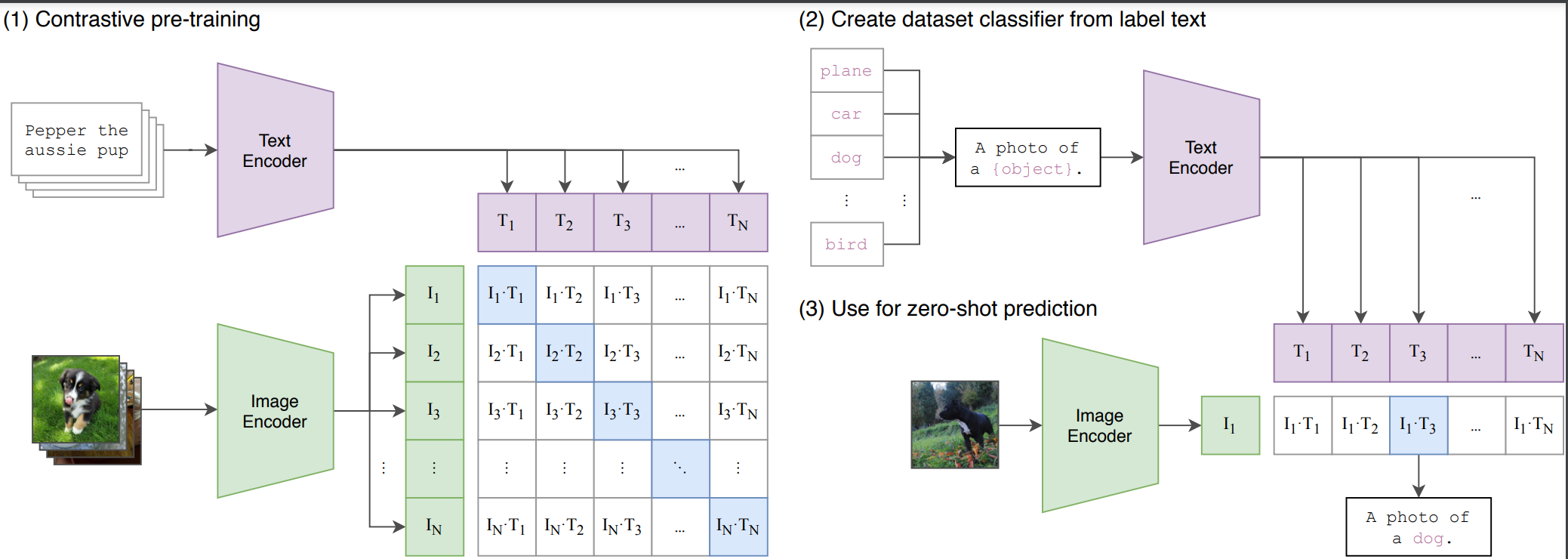
Dual Encoder Architecture: CLIP uses a dual-encoder system: one for images and one for text. The image encoder is usually a Vision Transformer (ViT) or a CNN that converts images into a fixed-size feature vector (embedding). The text encoder is usually a Transformer-based model like BERT or GPT, which tokenizes and converts text (e.g., captions or labels) into a similar embedding.
Contrastive Learning Objective: During training, CLIP is fed pairs of images and text descriptions. The goal is to learn embeddings where corresponding images and text are close together in the shared space, and non-matching pairs are far apart. This is achieved using a contrastive loss function, which maximizes the similarity between correct image-text pairs and minimizes the similarity for incorrect ones. The model effectively learns which descriptions go with which images.
Advantages of CLIP#
Zero-Shot Learning: Once trained, CLIP can be used in a zero-shot manner for a wide range of tasks without needing task-specific fine-tuning. For example:
For image classification: you can provide text prompts describing possible classes (e.g., “a photo of a cat,” “a photo of a dog”). The model then matches the image with the class whose description is closest in the shared embedding space.
For image-text retrieval: CLIP can retrieve the most relevant image for a given text prompt or vice versa, based on their learned embeddings.
Multimodal Representations: CLIP’s shared embedding space allows for cross-modal understanding (the model can handle tasks involving both images and text). For example, given a complex query like “a picture of a sunset with a lighthouse,” CLIP can find relevant images even if the specific combination was not seen during training.
Drawbacks of CLIP#
Computational Resources: Training CLIP requires significant computational resources and large-scale datasets, making it challenging for individual researchers or small teams to replicate the results.
Data Requirements: CLIP benefits from diverse and extensive datasets to learn robust image-text associations. Limited or biased training data can affect its performance on certain tasks.
Interpretability: While CLIP is effective, the learned embeddings may not be as interpretable as those from models like Vision Transformers, which provide more explicit spatial information about images.
Recent Advancements in Image Tokenization#
The field of image tokenization is rapidly evolving, with new methods and architectures pushing the boundaries of what’s possible in computer vision. Here are some recent advancements that are shaping the future of image tokenization:
SigLIP: Sigmoid Loss for Language Image Pre-Training#
SigLIP is a new approach to language-image pre-training that uses a simple pairwise Sigmoid loss to learn image-text embeddings. It’s based on CLIP’s contrastive learning framework but introduces a more efficient loss function that operates solely on image-text pairs without requiring global view normalization. This allows for scaling up the batch size and improved performance at smaller batch sizes.[10]
PaLI-3 Vision Language Models#
PaLI - 3 is a “smaller, faster, and stronger” vision language model that outperforms larger models on various multimodal benchmarks. It uses the contrastive pre-training approach from SigLIP and demonstrates superior performance on tasks like localization and visually-situated text understanding. PaLI-3 is designed to be more efficient and effective than larger models while maintaining strong performance across a range of vision-language tasks.[11]
PaliGemma#
Based on the success of PaLI-3, PaliGemma is an open Vision-Language Model (VLM) developed by Google that combines the SigLIP Vision Encoder and the Gemma-2B language model. PaliGemma is designed to be a broadly knowledgeable and versatile base model that performs well across a wide range of open-world tasks. It achieves strong performance on various vision-language tasks and is effective for transfer learning.[12]
LLaMA 3.2#
Llama 3.2, part of the advanced LLaMA model series, employs an innovative dual-token strategy for image tokenization, utilizing context and content tokens to efficiently process visual data within its language model framework
Dual-Token Strategy#
The dual-token strategy employed by Llama 3.2 involves generating two distinct types of tokens for each image:
Context Token: Captures the overall context of the image based on user input, providing a broader understanding of the visual content’s theme.
Content Token: Encapsulates specific visual cues and features within the image, allowing for detailed analysis of individual elements.
This approach significantly reduces computational burdens while preserving essential information, particularly beneficial when processing long sequences or complex visual data such as videos[13]. By utilizing this method, Llama 3.2 can efficiently handle multi-modal inputs, combining text and images seamlessly within its language processing framework [14].
Visual-Language Integration#
The integration of visual tokens into Llama 3.2’s language processing framework enables seamless interaction between visual and textual data. This is achieved by aligning the output of visual encoders with the language model’s embedding space [15] [16]. The process allows for effective handling of multi-modal inputs, combining images and text for tasks such as image captioning and visual question answering. By leveraging this integration, Llama 3.2 can process and understand complex visual information alongside textual data, enhancing its capabilities in multi-modal reasoning and analysis.
Performance Enhancements#
The advanced tokenization strategy employed by Llama 3.2 not only improves efficiency but also enhances the model’s performance on various benchmarks related to image and video understanding. This approach has shown competitive results in tasks such as image recognition and caption generation, demonstrating its capability to process and understand complex visual information [17], [18]. The model’s ability to handle hour-long videos and push the upper limit of visual processing with an extra context token represents a significant advancement in the field of Vision Language Models (VLMs) [18].
Challenges and Future Directions#
While image tokenization has made significant progress, several challenges and opportunities remain for further research and development:
Fine-grained Understanding: Enhancing models’ ability to capture fine-grained details and subtle features in images, especially in complex scenes or ambiguous contexts. This requires more sophisticated tokenization methods and architectures.
Multimodal Integration: Improving the integration of visual information with other modalities like text, audio, or sensor data. This will enable the development of more comprehensive and context-aware AI systems.
Interpretability and Explainability: Enhancing the interpretability of image tokenization methods to understand how models make decisions and provide meaningful explanations for their predictions.
Efficiency and Scalability: Developing more efficient and scalable image tokenization techniques that can handle large-scale datasets and complex visual tasks without compromising performance.
Robustness and Generalization: Ensuring that image tokenization methods are robust to variations in data, lighting conditions, viewpoints, and other factors, leading to more generalizable models.
Ethical and Fair AI: Addressing ethical considerations and fairness issues related to image tokenization, such as bias, privacy, and transparency in AI systems. This is crucial for compliance with guidelines and regulations like GDPR and the European AI Act.
Conclusion#
Image tokenization has become a basis of modern computer vision and AI, transforming how we process and interpret visual data. From discrete hard tokens to flexible soft tokens, these techniques have enabled more efficient processing, improved scalability, and enhanced cross-modal applications.
Models like Vision Transformers (ViT) and CLIP have significantly advanced our ability to understand and work with images, while recent innovations such as SigLIP, PaLI-3, and PaliGemma are pushing the boundaries even further. These developments are making sophisticated AI systems more accessible and effective across a wide range of vision-language tasks.
However, challenges persist in areas like fine-grained understanding, multimodal integration, and model interpretability. As research continues, we can expect image tokenization to play a more important role in shaping the next generation of AI systems, with applications ranging from autonomous vehicles, multi-modal AI assistants and more.
Resources#
An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. - One of the earliest examples of using for Vision Transformers (ViT) used in image recognition tasks.
Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.. This is the original paper on CLIP by OpenAI. It introduces the concept of contrastive language-image pretraining.
SigLIP: Sigmoid Loss for Language Image Pre-Training.. A new approach to language-image pre-training that uses a pairwise Sigmoid loss. SigLIP improves efficiency and performance in image-text embedding learning and serves as a foundation for new models.
PaLI-3: Smaller, Faster, Stronger Vision Language Models.. A vision language model that outperforms larger models on various multimodal benchmarks.
PaliGemma: An Open Vision-Language Model.. This is the paper introducing PaliGemma, the open Vision-Language Model developed by Google.
References#
Here are the references used in this guide: